工业蒸汽量预测2
1.数据包引入import matplotlib.pyplot as pltnimport seaborn as snsnimport pandas as pdnimport numpy as npnfrom scipy impo
1.数据包引入
import matplotlib.pyplot as pltnimport seaborn as snsnimport pandas as pdnimport numpy as npnfrom scipy import statsnfrom sklearn.model_selection import train_test_splitnfrom sklearn.model_selection import GridSearchCV, RepeatedKFoldnfrom sklearn.model_selection import cross_val_score, cross_val_predict, KFoldnfrom sklearn.metrics import make_scorer, mean_squared_errornfrom sklearn.linear_model import LinearRegression, Lasso, Ridge, ElasticNetnfrom sklearn.svm import LinearSVR, SVRnfrom sklearn.neighbors import KNeighborsRegressornfrom sklearn.ensemble import RandomForestRegressornfrom sklearn.ensemble import GradientBoostingRegressor, AdaBoostRegressornfrom xgboost import XGBRegressornfrom sklearn.preprocessing import PolynomialFeatures, MinMaxScaler, StandardScaler
2.数据载入
pd.set_option("display.max_rows", None) # None时不限制数量npd.set_option("display.max_columns", None)npd.set_option("display.width", 1000)nplt.rcParams["axes.unicode_minus"] = Falsensns.set_style("white", {"font.sans-serif": ["simhei", "Arial"]}) # 解决中文不能显示问题nnndata_train = pd.read_csv("./zhengqi_train.txt", sep="t", encoding="utf-8")ndata_test = pd.read_csv("./zhengqi_test.txt", sep="t", encoding="utf-8")ndata_train["oringin"] = "train"ndata_test["oringin"] = "test"ndata_all = pd.concat([data_train, data_test], axis=0, ignore_index=True)n# print(data_all.head())n# print(data_all.tail())
3.数据探查
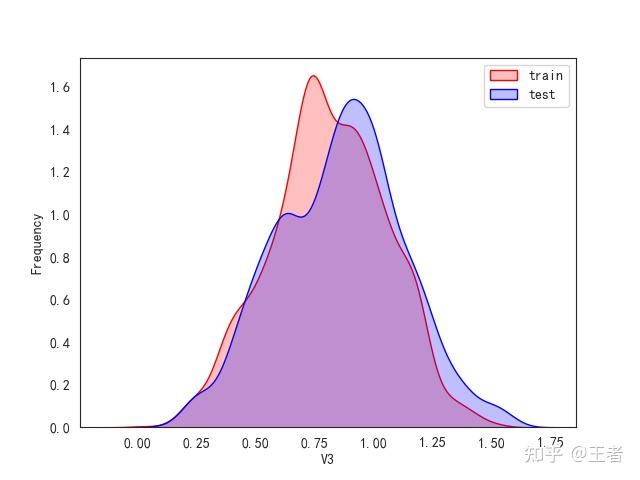
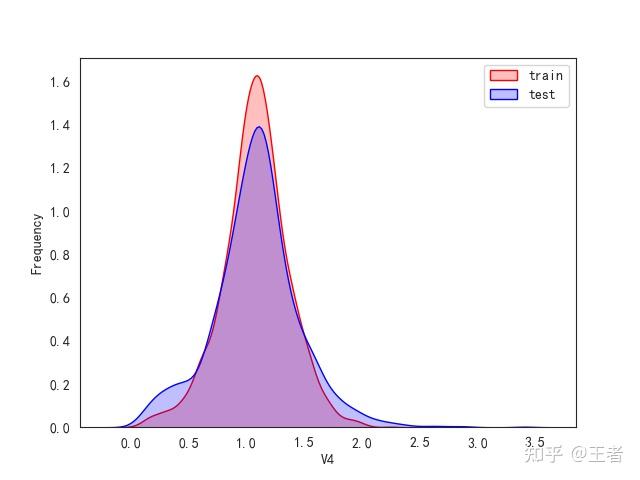
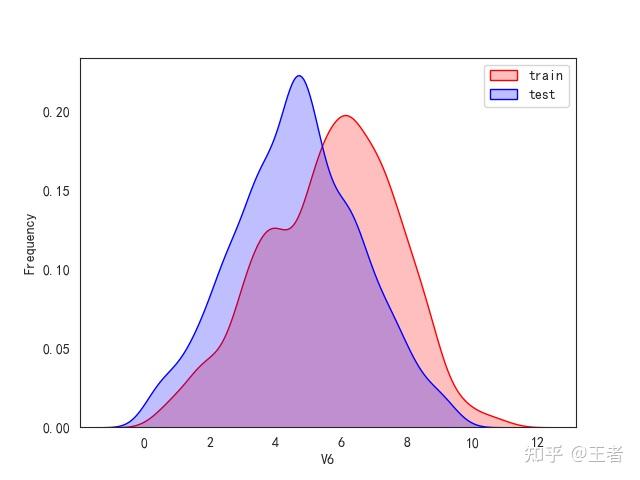
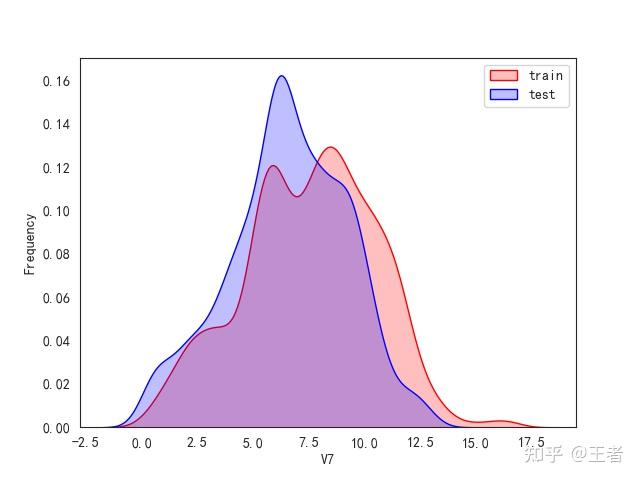
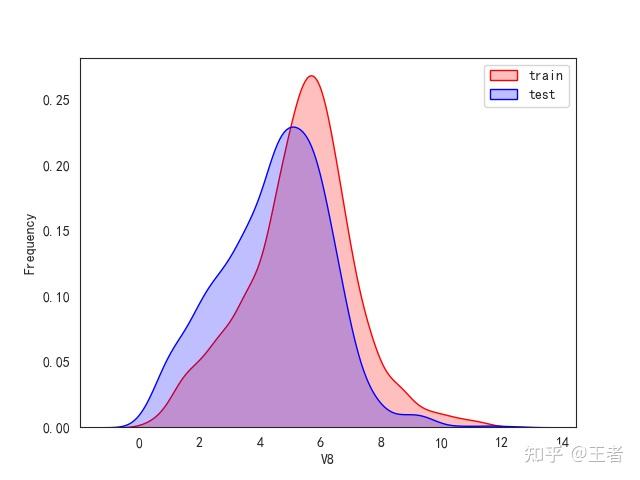
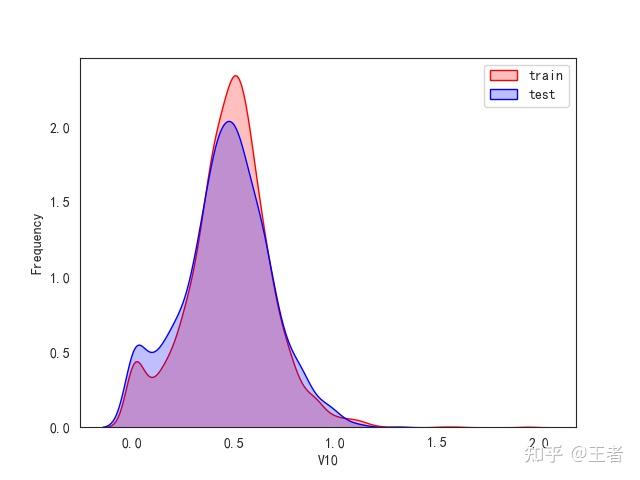
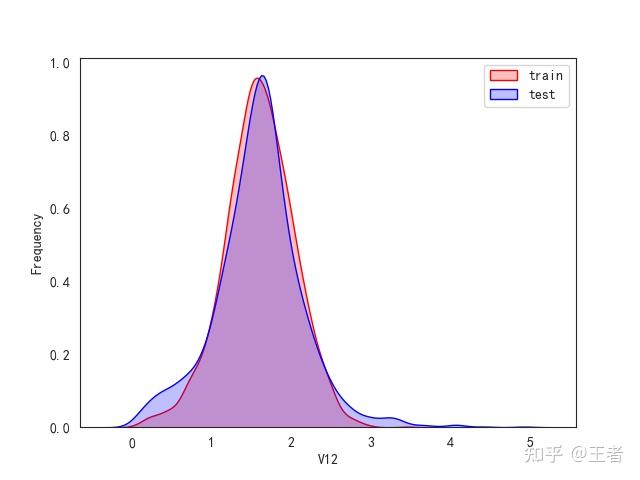
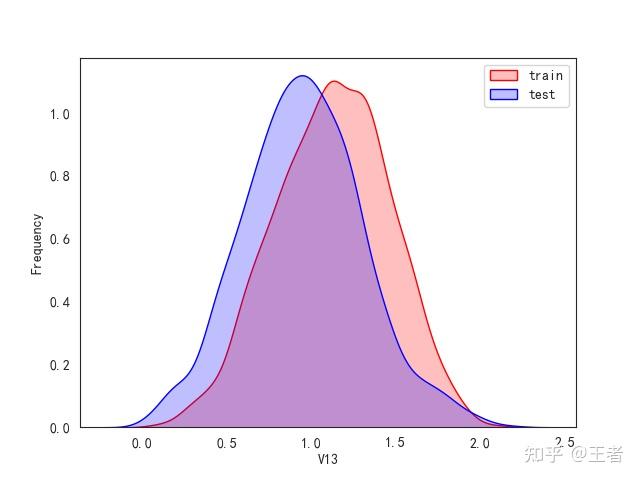
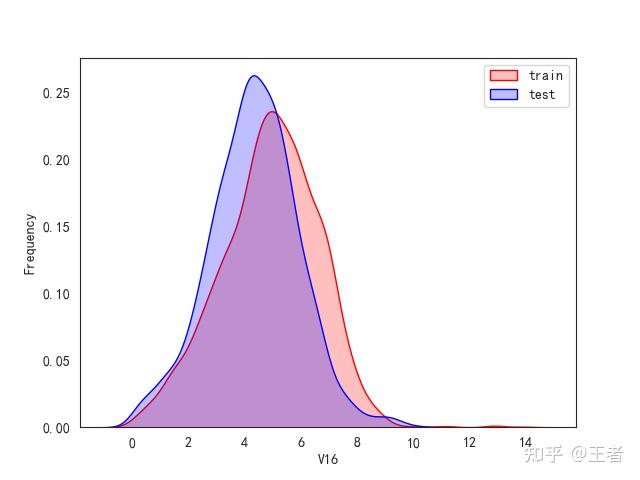
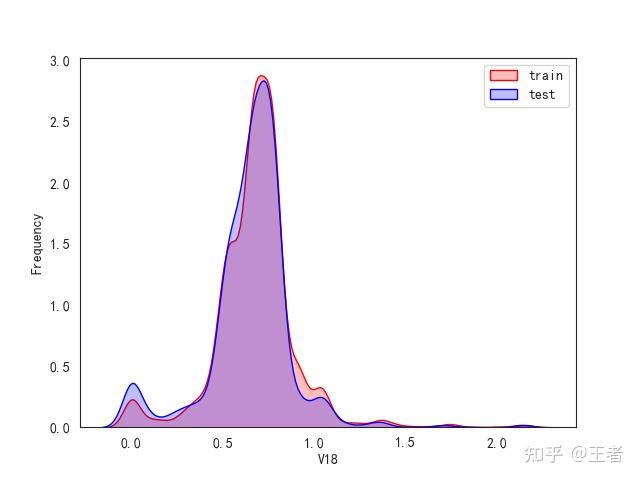
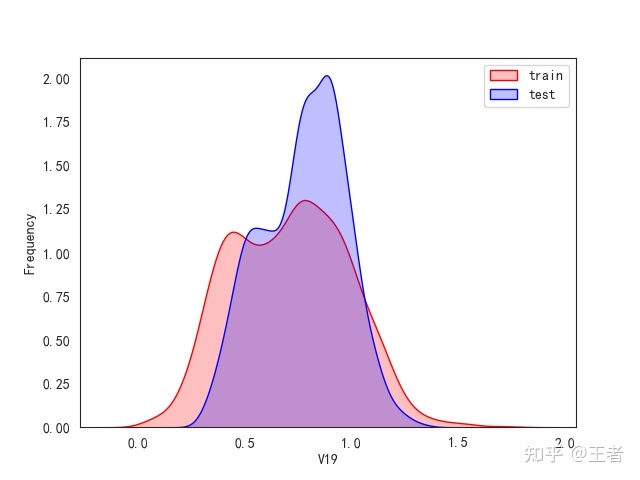
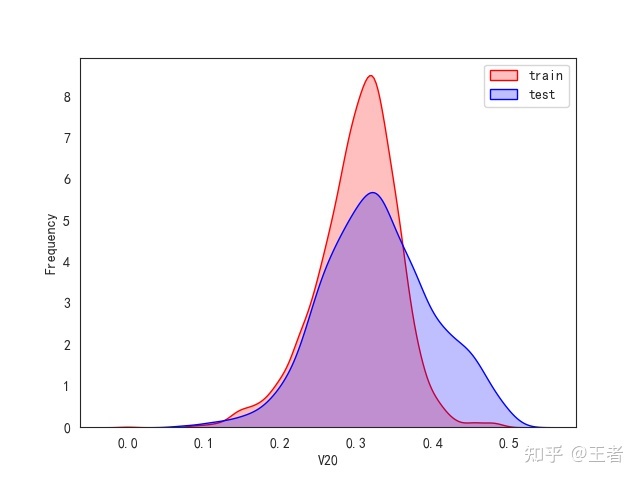
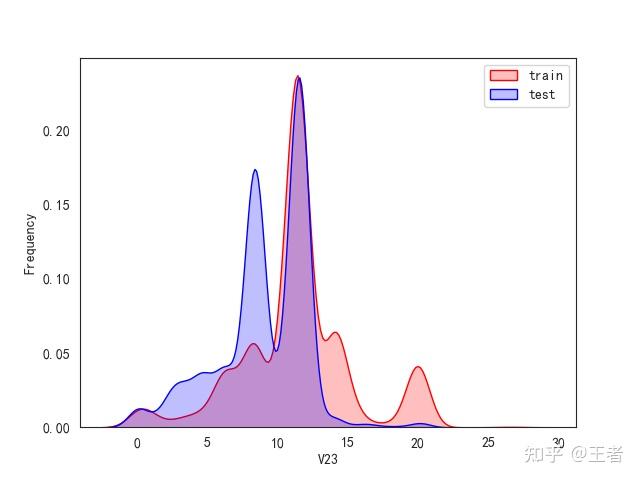
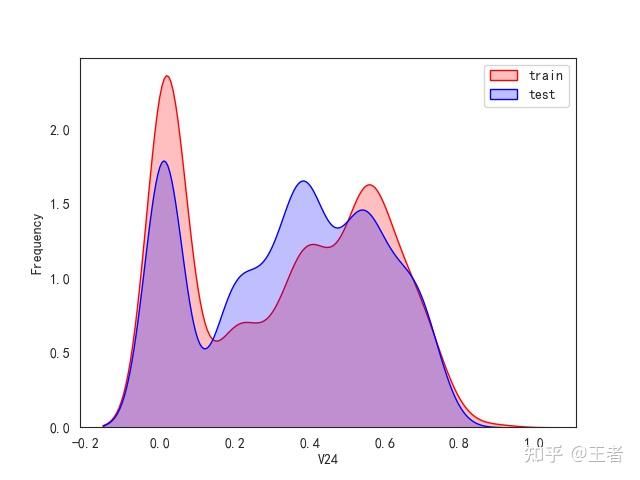
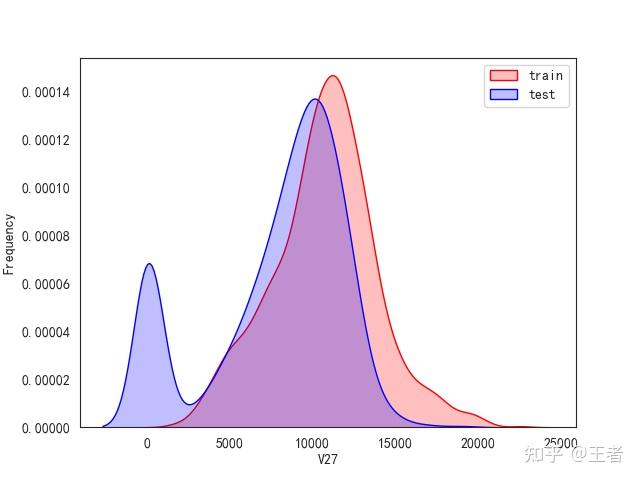
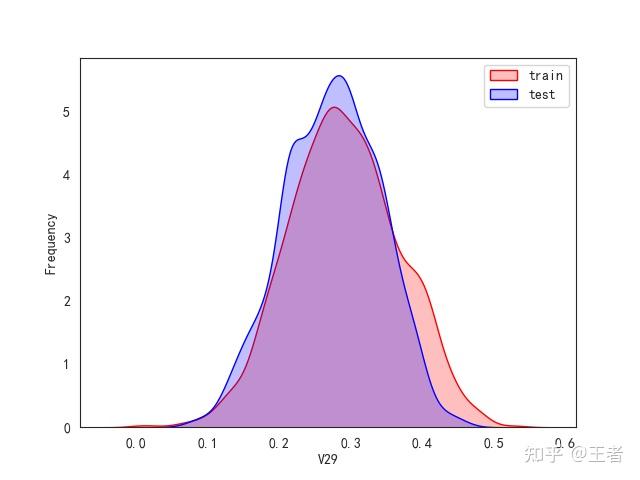
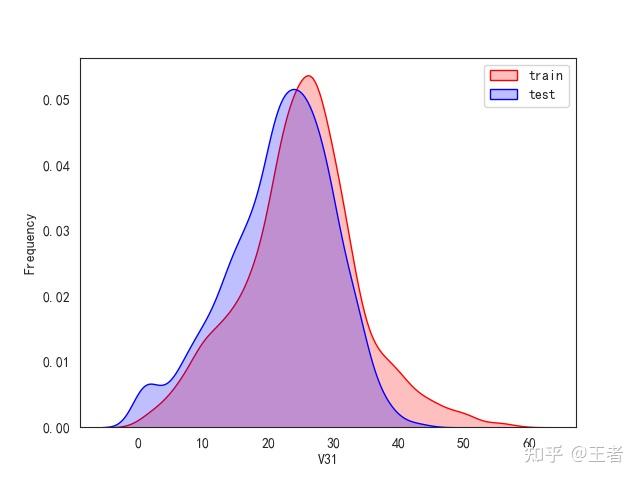
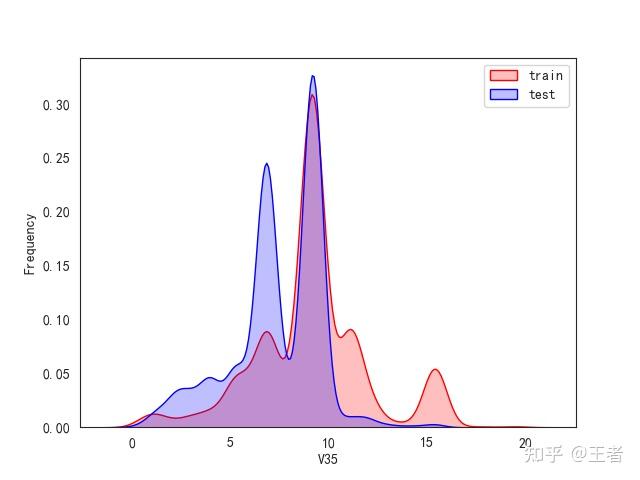
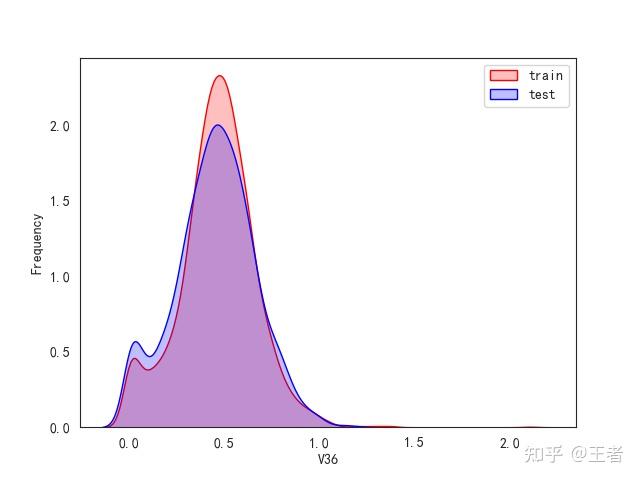
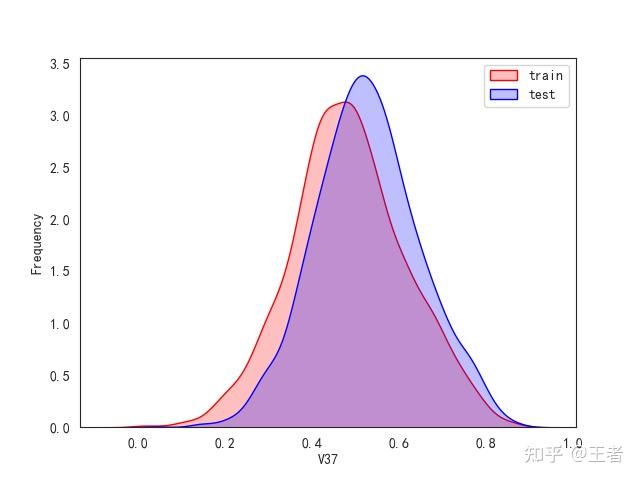
3.1训练集和测试集数据分布
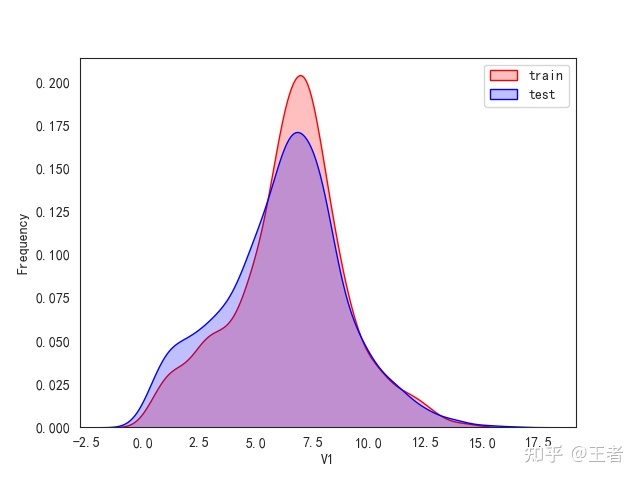
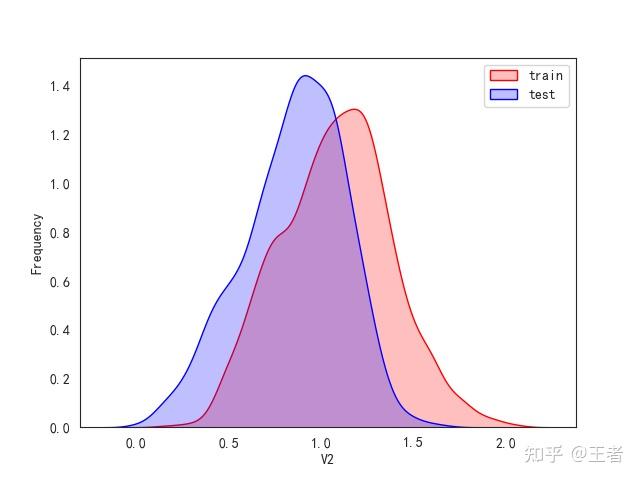
for col in data_all.columns[0:-2]:n g = sns.kdeplot(data_all[col][(data_all["oringin"] == "train")], color="Red", shade=True)n g = sns.kdeplot(data_all[col][(data_all["oringin"] == "test")], color="Blue", shade=True, ax=g)n g.set_xlabel(col)n g.set_ylabel("Frequency")n g.legend(["train", "test"])n plt.show()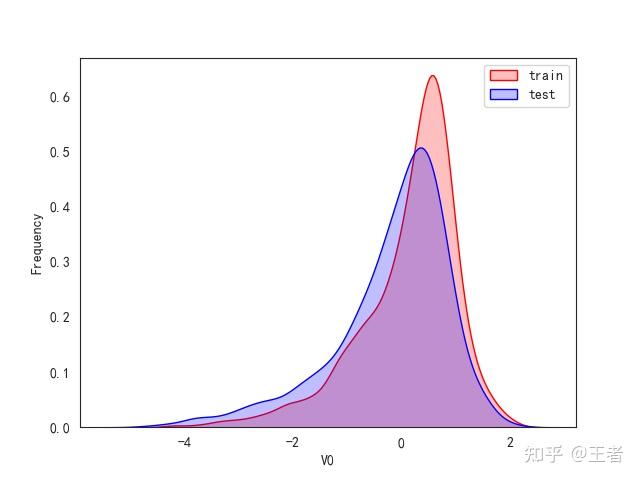
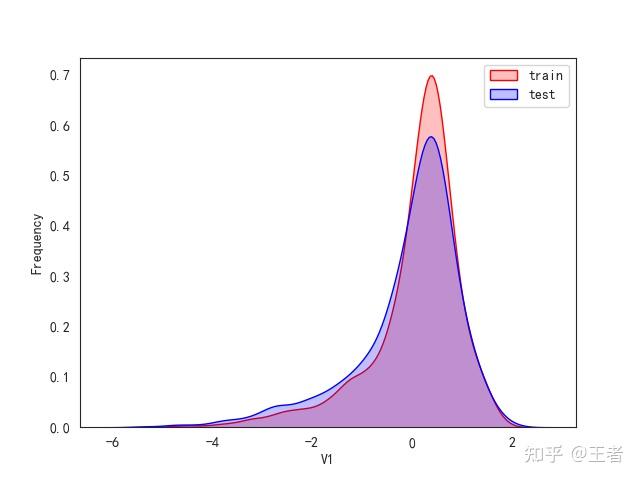
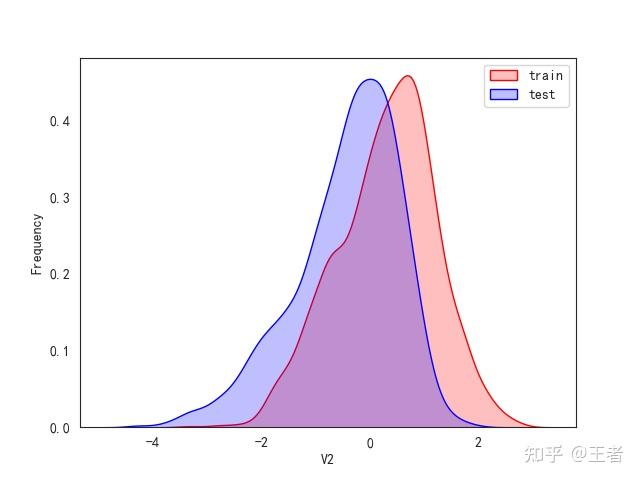
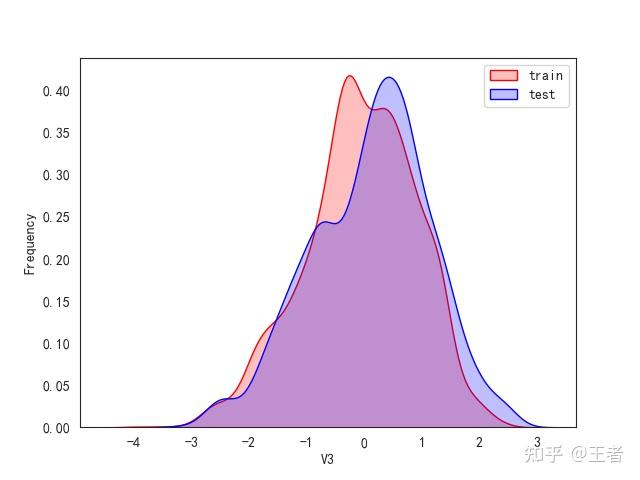
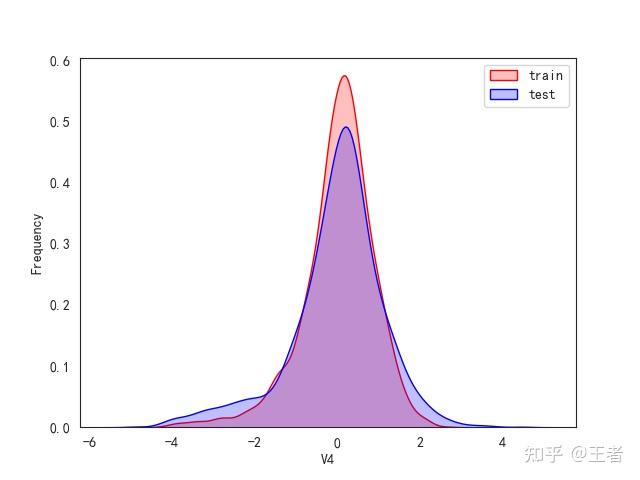
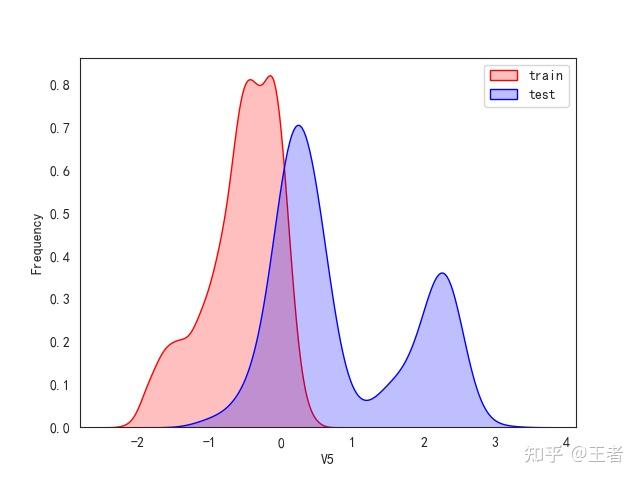
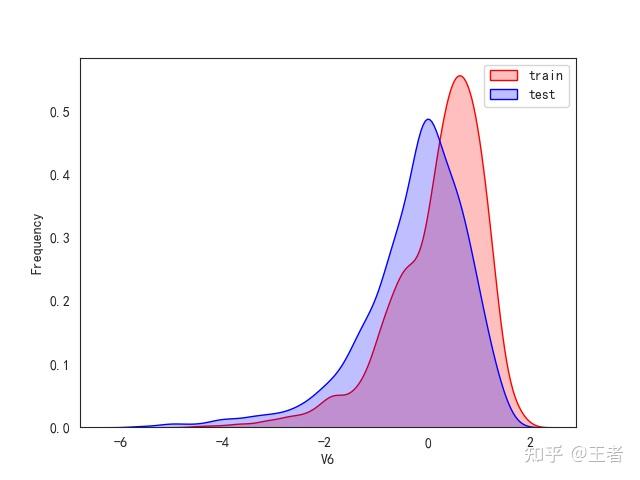

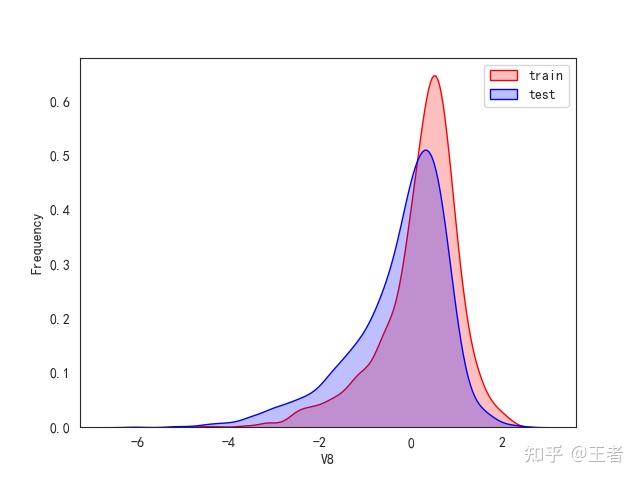
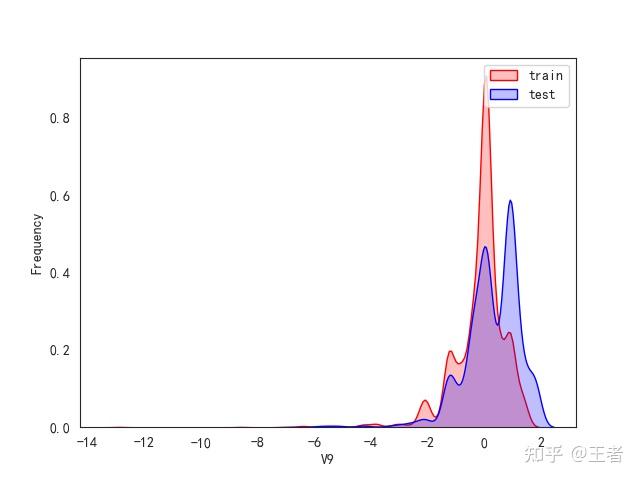
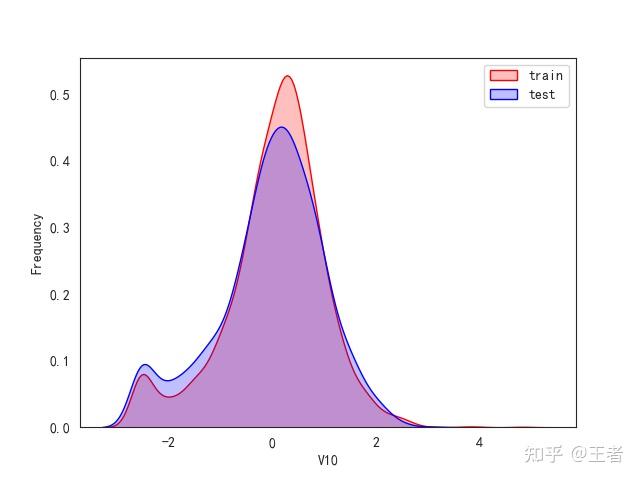
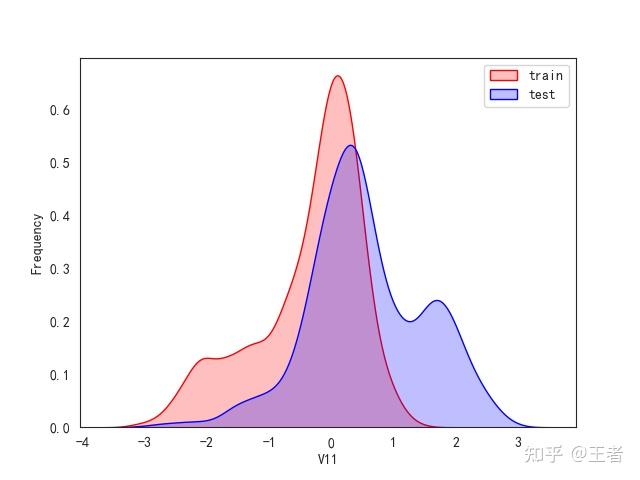
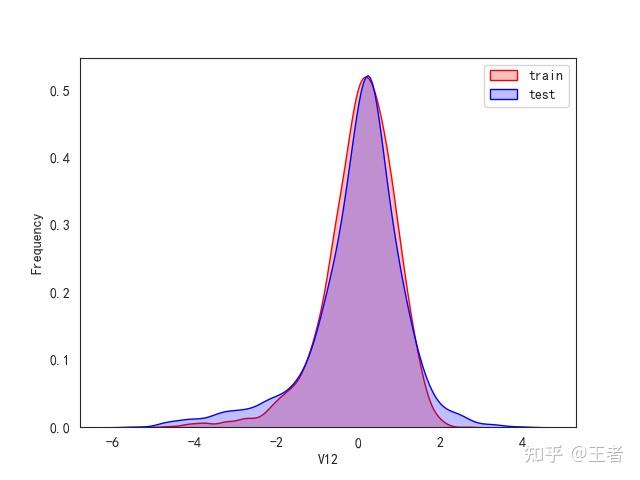
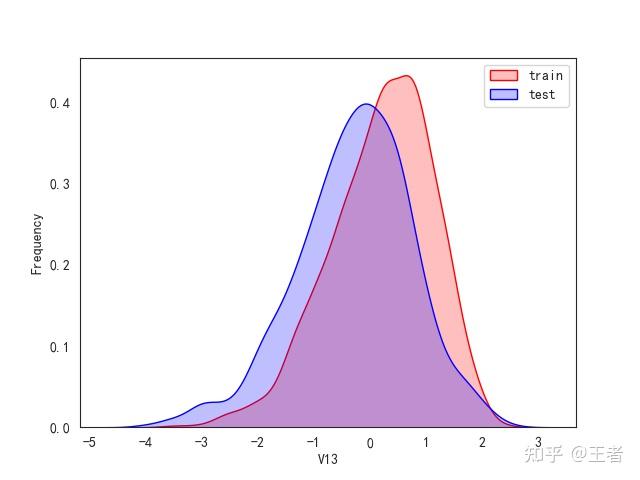
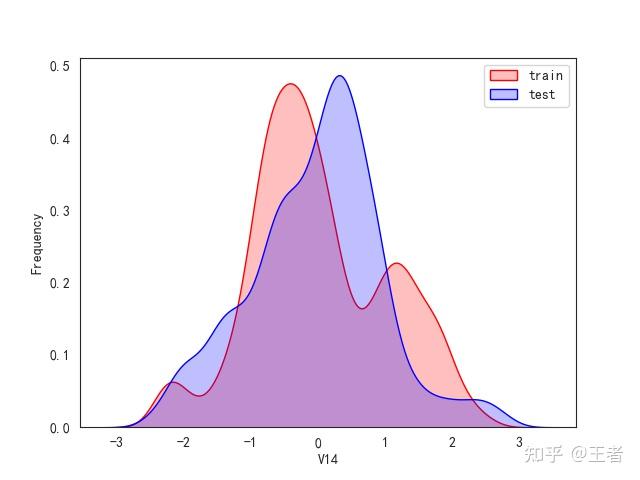
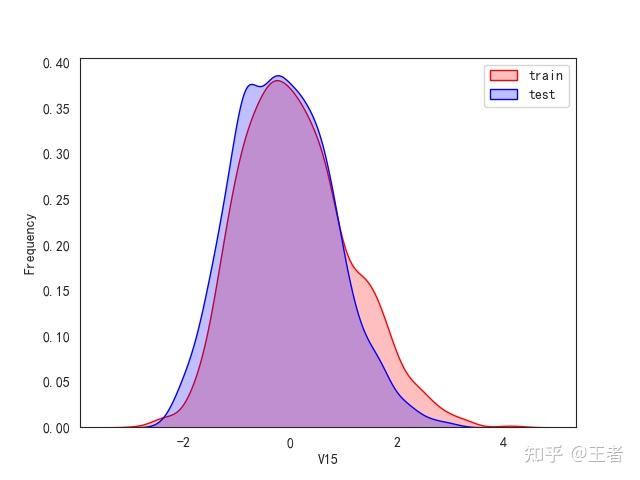
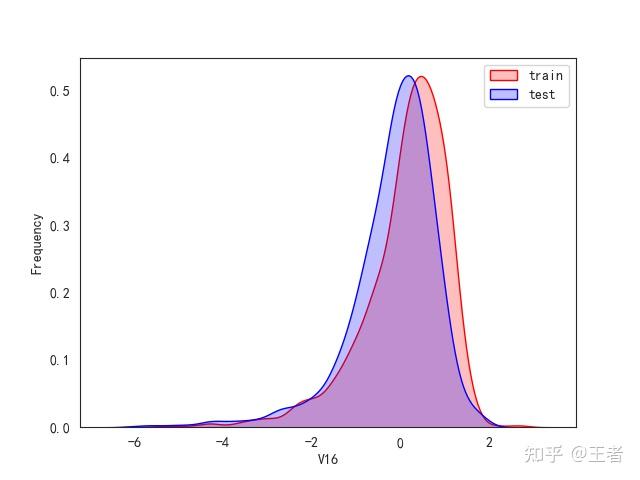
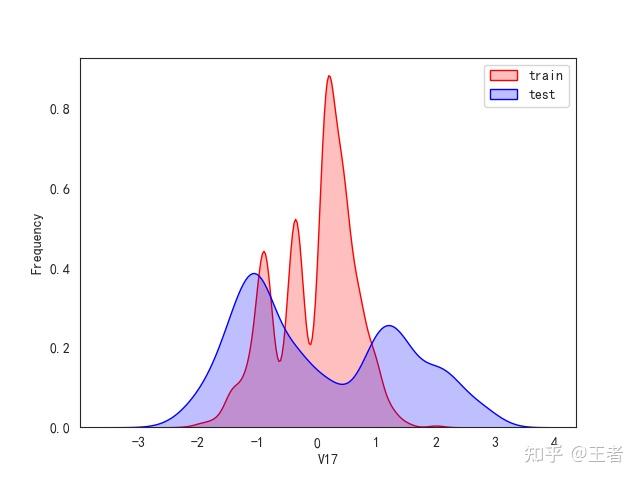
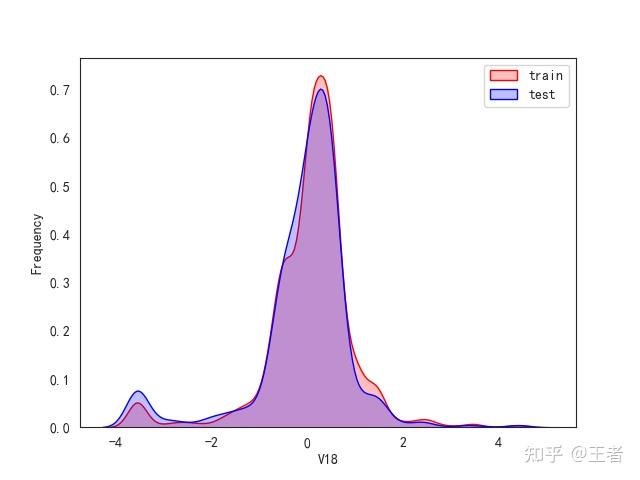
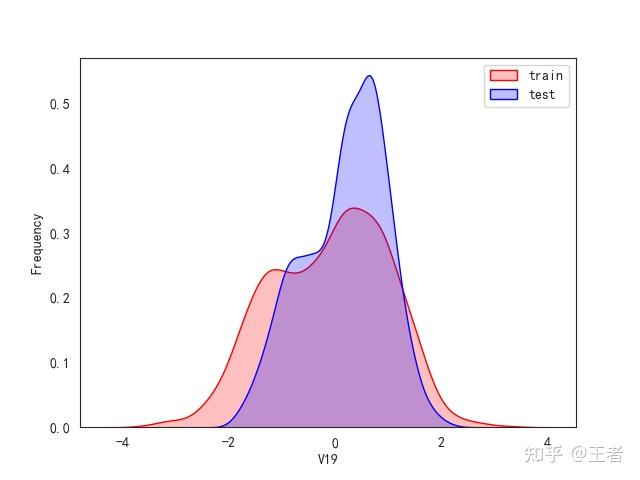
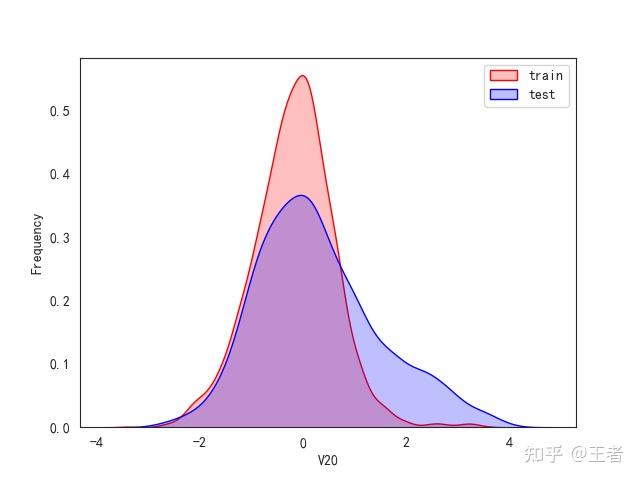
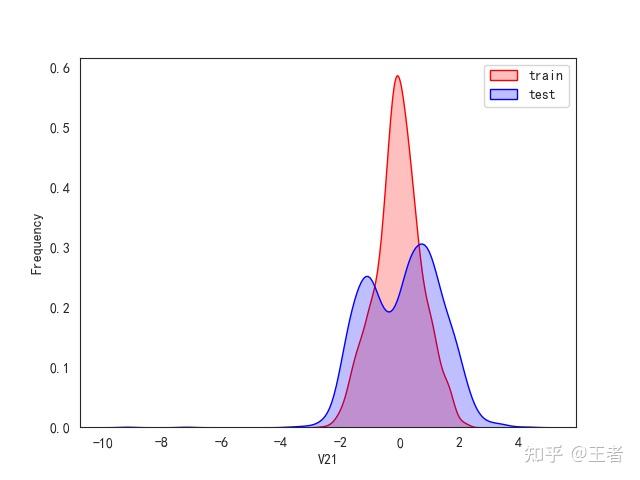
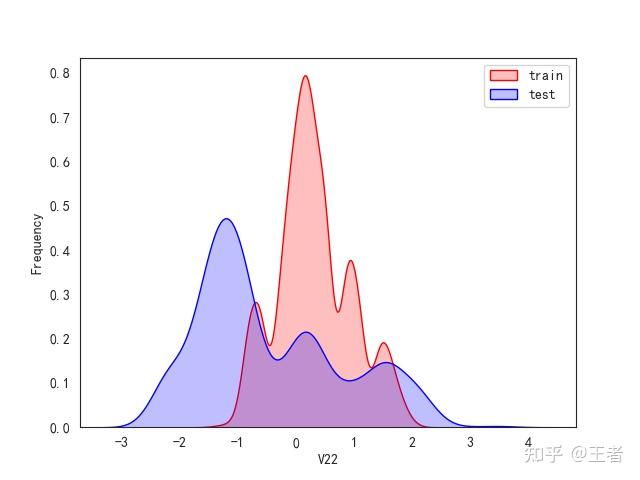
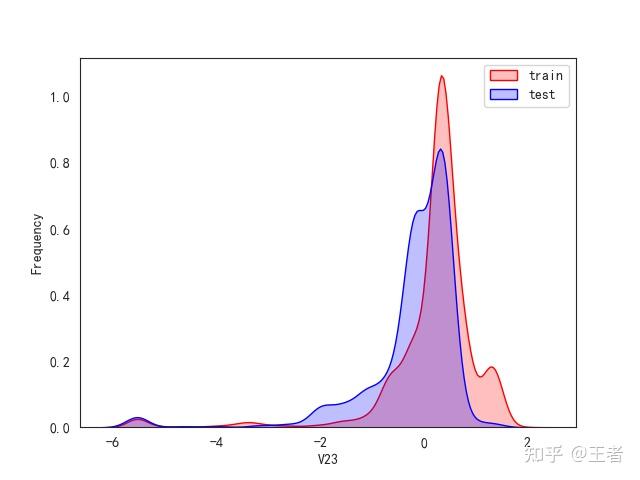
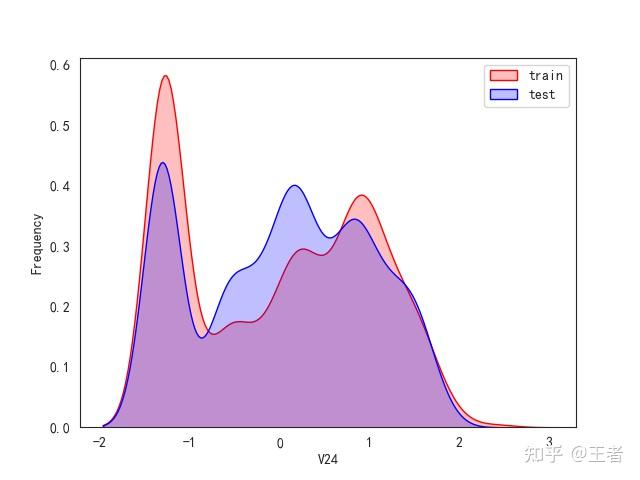
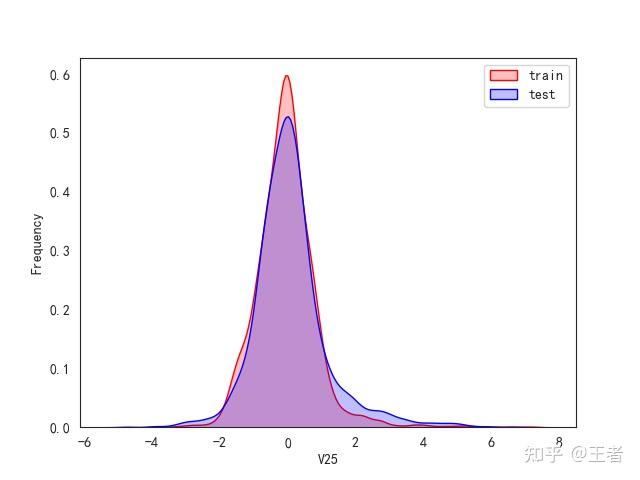
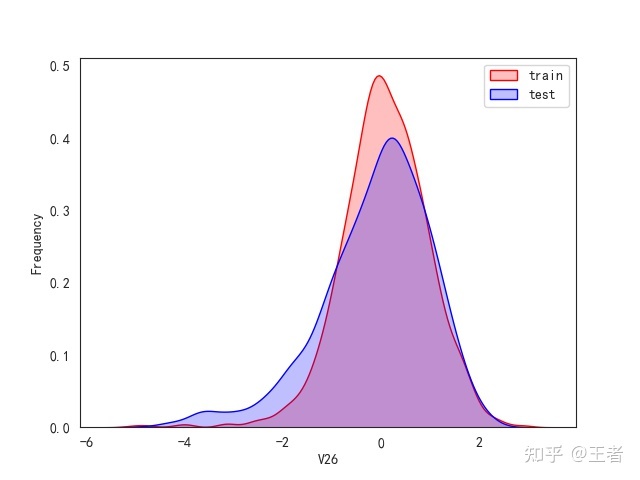
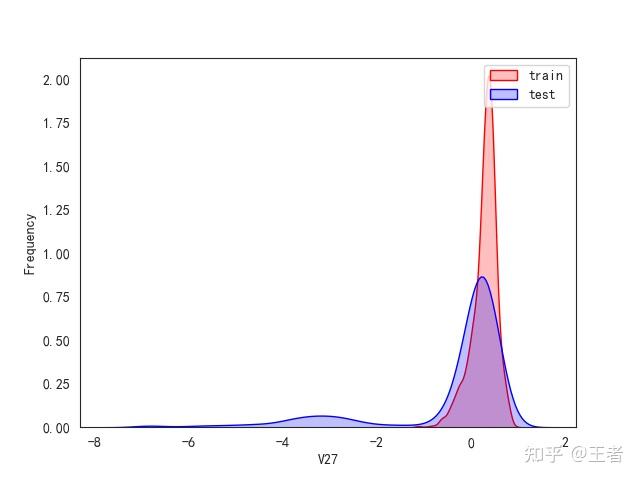
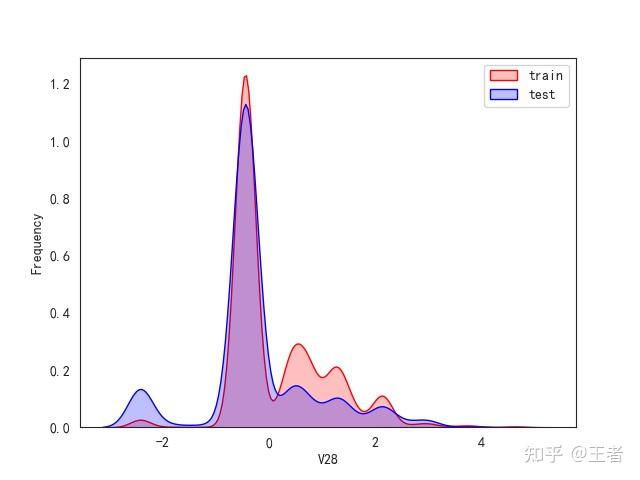

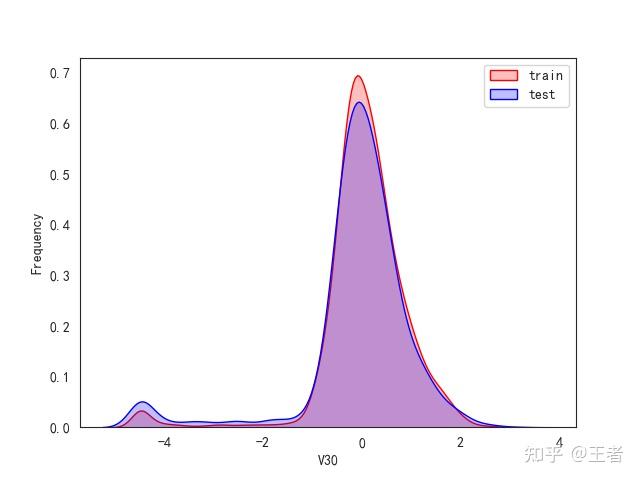
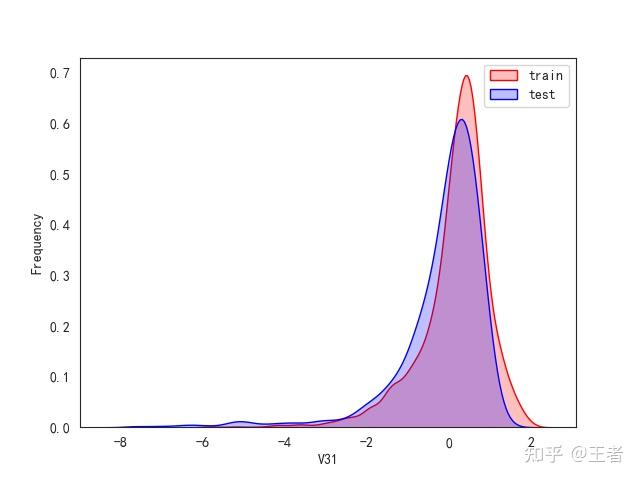
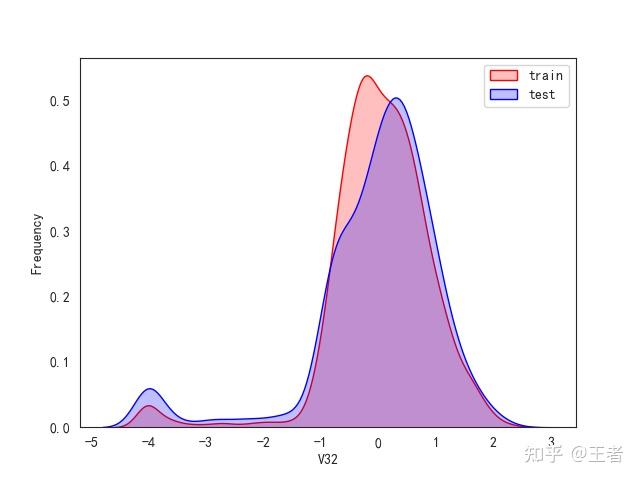
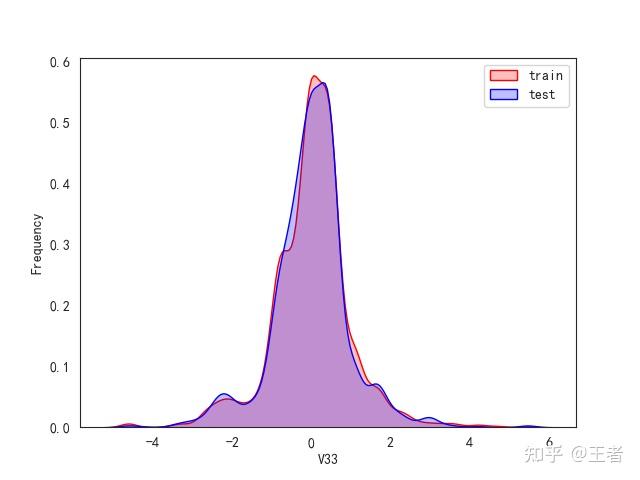
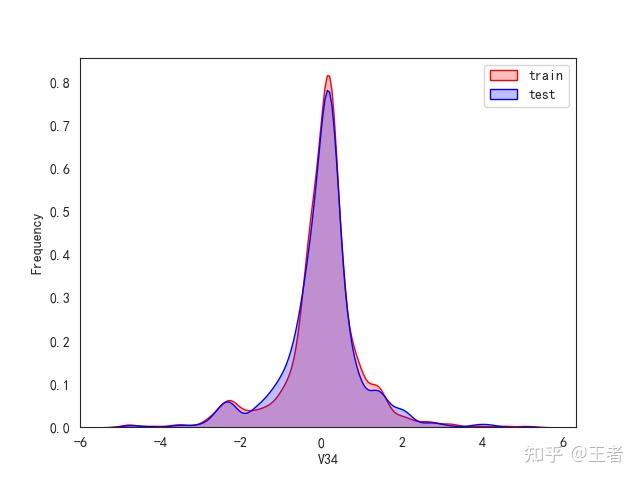
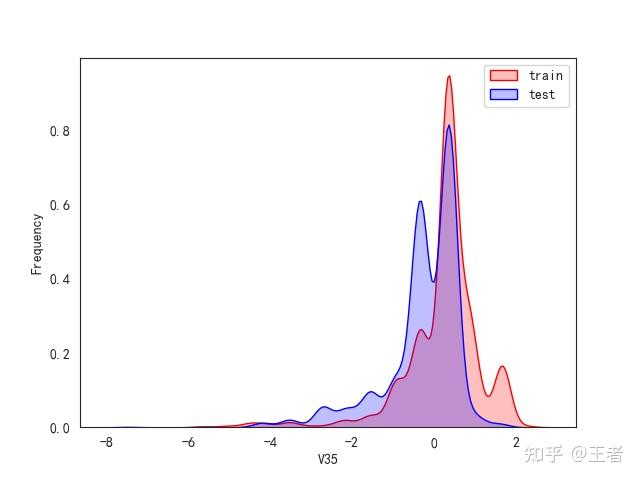
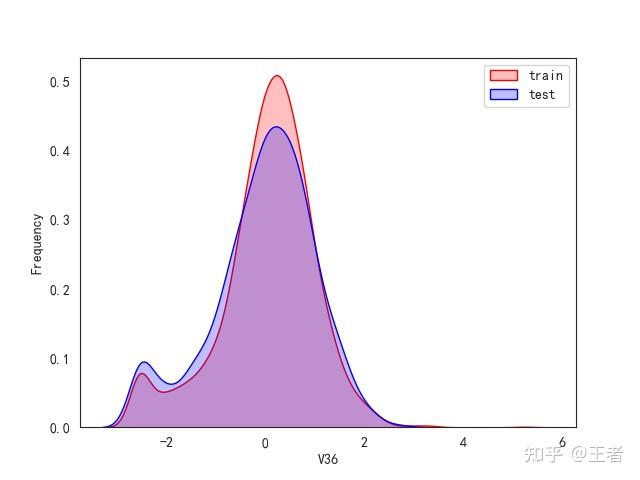
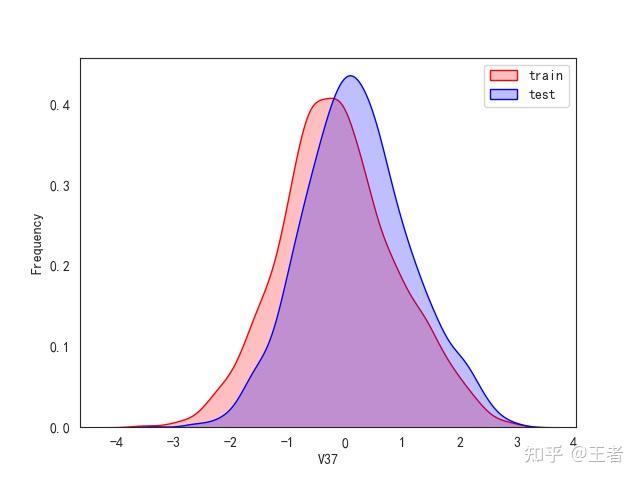
删除特征V5,V9,V11,V17,V22,V28
data_all.drop(["V5", "V9", "V11", "V17", "V22", "V28"], axis=1, inplace=True)
再看下数据分布情况:
data_train1 = data_all[data_all["oringin"] == "train"].drop("oringin", axis=1)nfcols = 2nfrows = len(data_train1.columns)nplt.figure(figsize=(5 * fcols, 4 * frows))ni = 0nfor col in data_train1.columns:n i += 1n ax = plt.subplot(frows, fcols, i)n sns.regplot(n x=col,n y="target",n data=data_train,n ax=ax,n scatter_kws={"marker": ".", "s": 3, "alpha": 0.3},n line_kws={"color": "k"},n )n plt.xlabel(col)n plt.ylabel("target")n i += 1n ax = plt.subplot(frows, fcols, i)n sns.distplot(data_train[col].dropna(), fit=stats.norm)n plt.xlabel(col)nplt.show()
# 找出相关程度nplt.figure(figsize=(20, 16)) # 指定绘图对象宽度和高度ncolnm = data_train1.columns.tolist() # 列表头nmcorr = data_train1[colnm].corr(method="spearman") # 相关系数矩阵,即给出了任意两个变量之间的相关系数nmask = np.zeros_like(mcorr, dtype=np.bool) # 构造与mcorr同维数矩阵 为bool型nmask[np.triu_indices_from(mask)] = True # 角分线右侧为Truencmap = sns.diverging_palette(220, 10, as_cmap=True) # 返回matplotlib colormap对象ng = sns.heatmap(n mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt="0.2f"n) # 热力图(看两两相似度)nplt.show()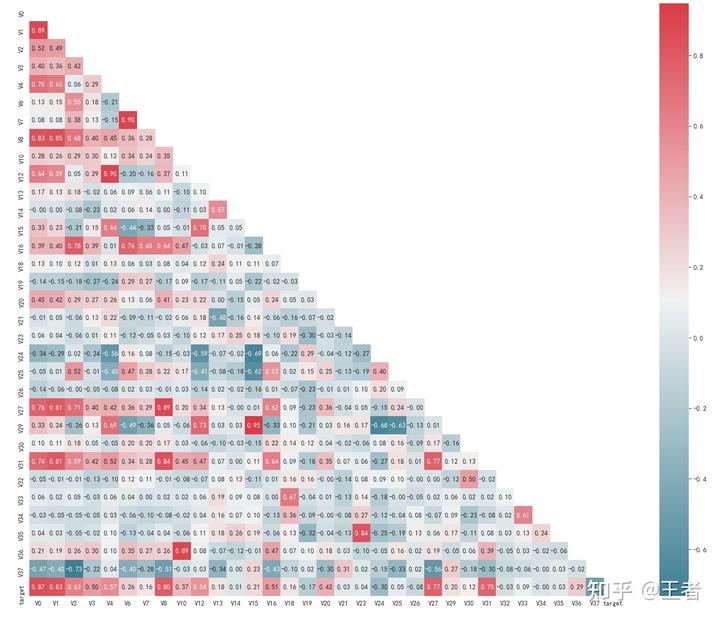
将与target的相关性绝对值<0.1的列剔除:
# Threshold for removing correlated variablesnthreshold = 0.1n# Absolute value correlation matrixncorr_matrix = data_train1.corr().abs()ndrop_col = corr_matrix[corr_matrix["target"] < threshold].indexnprint(drop_col)ndata_all.drop(drop_col, axis=1, inplace=True)nprint(data_all.columns)
标准正态化:
# normalise numeric columnsncols_numeric = list(data_all.columns)ncols_numeric.remove("oringin")nnn# 计算标准分数ndef scale_minmax(col):n return (col - col.min()) / (col.max() - col.min())nnnscale_cols = [col for col in cols_numeric if col != "target"]ndata_all[scale_cols] = data_all[scale_cols].apply(scale_minmax, axis=0)nprint(data_all[scale_cols].describe())

Box-Cox变换:
# Check effect of Box-Cox transforms on distributions of continuous variablesnfcols = 6nfrows = len(cols_numeric) - 1nplt.figure(figsize=(4 * fcols, 4 * frows))ni = 0nfor var in cols_numeric:n if var != "target":n dat = data_all[[var, "target"]].dropna()n i += 1n plt.subplot(frows, fcols, i)n sns.distplot(dat[var], fit=stats.norm)n plt.title(var + " Original")n plt.xlabel("")nn i += 1n plt.subplot(frows, fcols, i)n _ = stats.probplot(dat[var], plot=plt)n plt.title("skew=" + "{:.4f}".format(stats.skew(dat[var])))n plt.xlabel("")n plt.ylabel("")nn i += 1n plt.subplot(frows, fcols, i)n plt.plot(dat[var], dat["target"], ".", alpha=0.5)n plt.title("corr=" + "{:.2f}".format(np.corrcoef(dat[var], dat["target"])[0][1]))nn i += 1n plt.subplot(frows, fcols, i)n trans_var, lambda_var = stats.boxcox(dat[var].dropna() + 1)n trans_var = scale_minmax(trans_var)n sns.distplot(trans_var, fit=stats.norm)n plt.title(var + " Tramsformed")n plt.xlabel("")nn i += 1n plt.subplot(frows, fcols, i)n _ = stats.probplot(trans_var, plot=plt)n plt.title("skew=" + "{:.4f}".format(stats.skew(trans_var)))n plt.xlabel("")n plt.ylabel("")nn i += 1n plt.subplot(frows, fcols, i)n plt.plot(trans_var, dat["target"], ".", alpha=0.5)n plt.title(n "corr=" + "{:.2f}".format(np.corrcoef(trans_var, dat["target"])[0][1])n )nplt.show()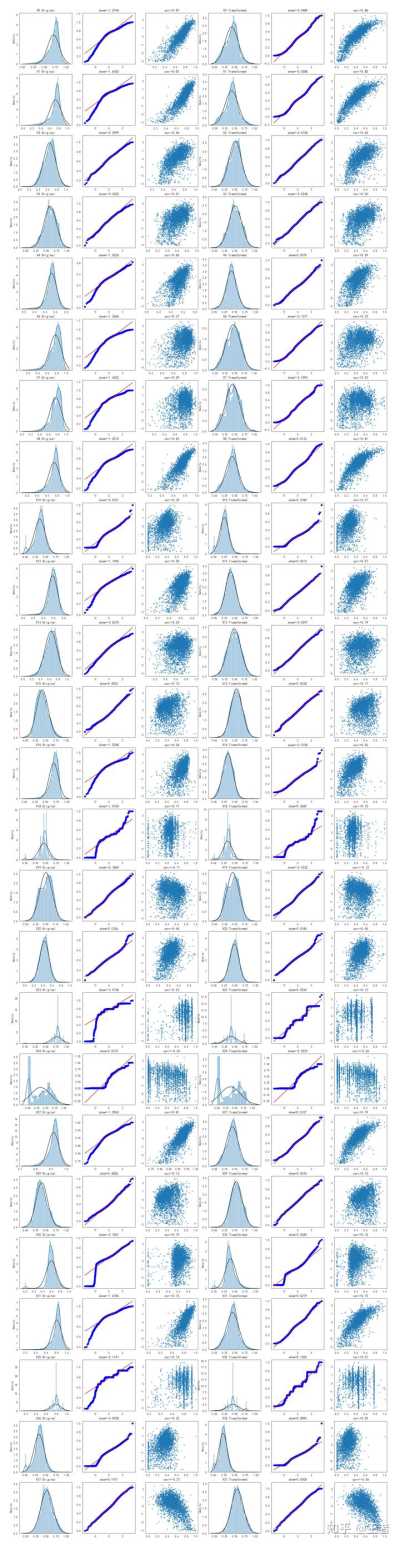
变换:
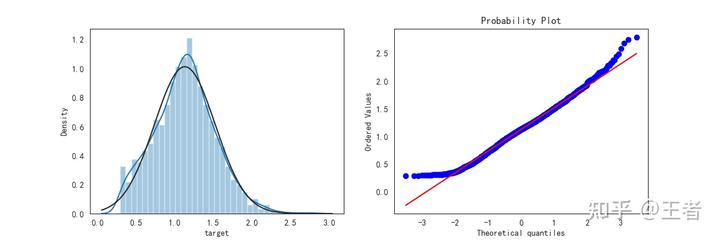
for col in cols_transform:n data_all.loc[:, col], _ = stats.boxcox(data_all.loc[:, col] + 1)n"""print(data_all.target.describe())nplt.figure(figsize=(12, 4))nplt.subplot(1, 2, 1)nsns.distplot(data_all.target.dropna(), fit=stats.norm)nplt.subplot(1, 2, 2)n_ = stats.probplot(data_all.target.dropna(), plot=plt)nplt.show()"""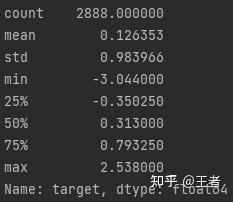
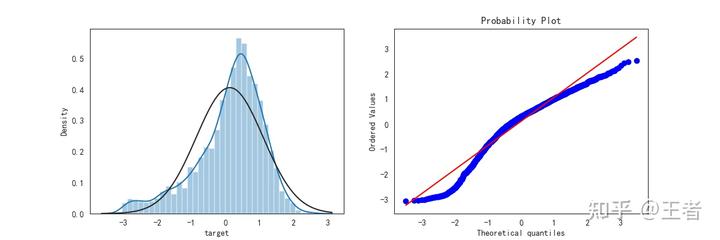
转换:
# Log Transform SalePrice to improve normalitynsp = data_train.targetndata_train.target1 = np.power(1.5, sp)nprint(data_train.target1.describe())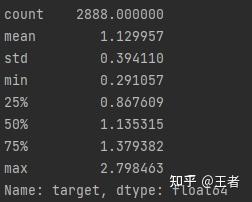
for column in data_all.columns[0:-2]:n g = sns.kdeplot(n data_all[column][(data_all["oringin"] == "train")], color="Red", shade=Truen )n g = sns.kdeplot(n data_all[column][(data_all["oringin"] == "test")],n ax=g,n color="Blue",n shade=True,n )n g.set_xlabel(column)n g.set_ylabel("Frequency")n g = g.legend(["train", "test"])n plt.show()


下一篇:燃气蒸汽发生器怎样比较环保







