
前言Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3Dcode:https://github.co
前言
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
code:https://github.com/nv-tlabs/lift-splat-shoot
LSS是ECCV 2020年的一篇从BEV角度做3D检测及规划的文章,是圈内公认的基于BEV做3D感知的开山之作。要搞明白基于BEV的3D目标检测方法,LSS是基础,有助于后续文章的理解,目前很多文章讲解LSS的流程和框架,我从自己理解的过程结合代码对这篇经典的文章做个解析,主要分析理解前两步,即Lift和Splat,废话少说,直接进入主题。
主要涉及几个问题
1、每个摄像头如何构建3D特征;
2、如何将构建的特征投影到BEV空间;
3、如何编码投影到BEV空间的特征。
以上的3个问题就涉及到Lift, Splat的操作,弄清了上述三个问题,就弄清了全文的操作。
从理论上来看,整个文章中解释Lift和Splat的部分是比较少的,大概也就一页半的篇幅。
下图就是Lift 和 Splat的流程。
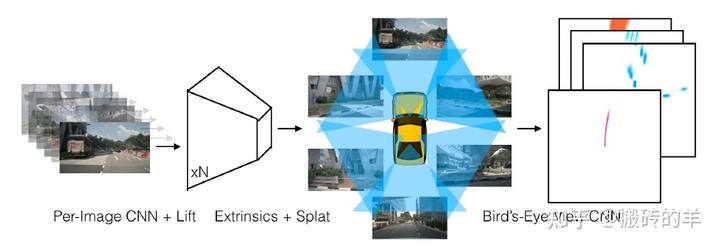
前置说明
输入:每个时刻下,环视摄像头的图像,摄像头的内外参,训练和测试中不需要任何深度传感器。
输出:对于3D目标检测来说,BEV视角下的3D坐标和目标类别。
构建3D特征
n个摄像头同一时刻的表示: 



每个摄像头相互是独立的,单目摄像头获得深度信息是个比较难的事情,那在Lift中的解决方法中,生成了每个像素所有深度的可能性特征。
首先,深度做了离散化的处理,每个像素的深度划分了D份,那这个像素的所有深度值为 


比如,一个摄像头拍摄到的图像的像素坐标为(h,w),这个像素点所对应的深度 

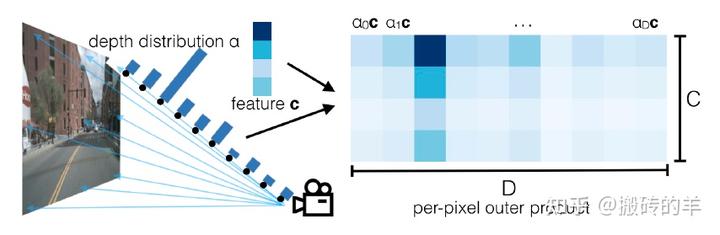
点云特征是如何构建,可以从代码上来看更清晰:
#这里是如何从2D图像特征转到3D相关的特征上ndef get_cam_feats(self, x):n """Return B x N x D x H/downsample x W/downsample x Cn """n B, N, C, imH, imW = x.shapenn # 首先将环视图像和batch拍在同一个维度上,因为每个摄像头的特征是相互独立的n x = x.view(B*N, C, imH, imW)n n # 这个函数是提取2D特征,并把特征与3D位置做关联,也就是Lift操作,下面的代码段解释是如何操作的。n x = self.camencode(x)n # camencode函数输出的特征是 (B*N) * CamC * D * feaH * feaW,将第一维B*N拆开n x = x.view(B, N, self.camC, self.D, imH//self.downsample, imW//self.downsample)n # 将channle维度放到最后一维上n x = x.permute(0, 1, 3, 4, 5, 2)n return x
class CamEncode(nn.Module):n def __init__(self, D, C, downsample):n super(CamEncode, self).__init__()n self.D = Dn self.C = Cn n # 构建的网络结构n self.trunk = EfficientNet.from_pretrained("efficientnet-b0")nn self.up1 = Up(320+112, 512)n # depthnet的channle是深度+特征维度n self.depthnet = nn.Conv2d(512, self.D + self.C, kernel_size=1, padding=0)nn def get_depth_dist(self, x, eps=1e-20):n # 得到深度的预测值,采用softmax预测哪个深度的概率大n return x.softmax(dim=1)nn def get_depth_feat(self, x):n x = self.get_eff_depth(x)n # Depthn x = self.depthnet(x)nn depth = self.get_depth_dist(x[:, :self.D])n # 这里是重点,将深度和特征做乘法,变为(B*N) * CamC * D * feaH * feaWn new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2)nn return depth, new_xnn def get_eff_depth(self, x):n ...n return xnn def forward(self, x):n depth, x = self.get_depth_feat(x)n # 返回深度和特征整合的特征,(B*N) * CamC * D * feaH * feaWn return x
构建的特征投影到BEV空间
从文章上讲的,主要是分2步,1)将构建的点云特征通过pillar的方式投影到预先构建的BEV的空间;2)对于在同一个pillar中重复的点云做融合。
还是从代码上来做解释说明:
xbound=[-50.0, 50.0, 0.5],n ybound=[-50.0, 50.0, 0.5],n zbound=[-10.0, 10.0, 20.0],n dbound=[4.0, 45.0, 1.0],n def create_frustum(self):n # make grid in image planen ## 输入网络的图片大小n ogfH, ogfW = self.data_aug_conf['final_dim']n fH, fW = ogfH // self.downsample, ogfW // self.downsamplen # 在 fH和fW上构建[4.0, 45.0, 1.0]的深度值n ds = torch.arange(*self.grid_conf['dbound'], dtype=torch.float).view(-1, 1, 1).expand(-1, fH, fW)n D, _, _ = ds.shapen #宽和高 按照输入网络的图片尺寸来构建n xs = torch.linspace(0, ogfW - 1, fW, dtype=torch.float).view(1, 1, fW).expand(D, fH, fW)n ys = torch.linspace(0, ogfH - 1, fH, dtype=torch.float).view(1, fH, 1).expand(D, fH, fW)nn # D x H x W x 3n # 构建成视锥,宽高的尺寸与输出特征一致n frustum = torch.stack((xs, ys, ds), -1)n return nn.Parameter(frustum, requires_grad=False)
接下来就是真正构建bev特征的过程:
## 这个函数构建BEV特征的入口,其中包含了2D 3D的投影关系 -> 2D特征提取,n ## 以及从2D特征构建3D特征 -> 特征投影到BEV空间的过程n def get_voxels(self, x, rots, trans, intrins, post_rots, post_trans):n ##参数说明: x是环视图片 B x N x 3 x orgH x orgWn ##rots、trans 每张图片对应的相机外参,旋转和平移n ##intrins 每张图片对应的相机内参n ##post_rots, post_trans 每张图片在训练过程中,图片数据增强中用到的旋转和平移nn ## 这个函数的目的,是为了找到每个相机中,视锥中的每个点对应在BEV空间中的位置关系。 n geom = self.get_geometry(rots, trans, intrins, post_rots, post_trans)n ## Lift的部分已经说明了n x = self.get_cam_feats(x)n ## 跟踪geom 和 x 构建bev特征n x = self.voxel_pooling(geom, x)n return xnn def get_geometry(self, rots, trans, intrins, post_rots, post_trans):n """Determine the (x,y,z) locations (in the ego frame)n of the points in the point cloud.n Returns B x N x D x H/downsample x W/downsample x 3n """n B, N, _ = trans.shapenn # undo post-transformation ## 视锥上加上数据增强的旋转和平移n # B x N x D x H x W x 3n ## 由于每个相机的视锥都一样的,所以这里的frustum所有图片都可以共用。n ## frustum矩阵也可以根据旋转平移矩阵的大小做broadcasen points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)n points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))nn # cam_to_egon ## 这里就是2D 3D转换中用的公式,在uv的坐标上乘上scale尺度的操作n points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],n points[:, :, :, :, :, 2:3]n ), 5)n ## 内参矩阵 * 外参的旋转矩阵n combine = rots.matmul(torch.inverse(intrins))n ## 相乘再加上平移举证,从而得到每个摄像头下视锥所对应的世界坐标系位置。n points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)n points += trans.view(B, N, 1, 1, 1, 3)n n #输出的point维度:B x N x D x H/downsample x W/downsample x 3n return pointsnn def voxel_pooling(self, geom_feats, x):n B, N, D, H, W, C = x.shapen Nprime = B*N*D*H*Wnn # flatten xn 将所有的特征拉平n x = x.reshape(Nprime, C)nn # flatten indicesn # 构建的世界坐标下的对应关系,做了平移没有负半轴的数,并限制了dx只有一个像素,同时long()是将数值变成整型。n # 将数值变为整型的目的是,知道了那些点是在BEV的同一个格子里,在同一个格子里的特征需要做特征融合n geom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long()n ## 和特征一样,将前面的维度都拉平,这里geom的位置关系和x的位置关系是一一对应的。n geom_feats = geom_feats.view(Nprime, 3)n #由于拉平后丢失了batch的信息,将batch id放在geom_feats的最后一维上。n batch_ix = torch.cat([torch.full([Nprime//B, 1], ix,n device=x.device, dtype=torch.long) for ix in range(B)])n geom_feats = torch.cat((geom_feats, batch_ix), 1)nn # filter out points that are outside boxn # 过滤掉超过bev空间的点n kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0])n & (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1])n & (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])n x = x[kept]n geom_feats = geom_feats[kept]nn # get tensors from the same voxel next to each othern # 判断哪些点是处于相同的格子里,ranks相同的值表示在同一个BEV的格子里n ranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B)n + geom_feats[:, 1] * (self.nx[2] * B)n + geom_feats[:, 2] * Bn + geom_feats[:, 3]n # 对得到的ranks排序的索引n sorts = ranks.argsort()n # 根据选择的点和排序后的索引选择x 和 geom_feats, 也对ranks排序n x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts]nn # cumsum trickn ## 这里就是跟踪ranks来做特征融合,如果有相同的rank,表示在同一个格子里需要做特征融合。n ## 融合后的特征与摄像头就没没关系了,所以这里geom_feats就没有N这个维度了n if not self.use_quickcumsum:n x, geom_feats = cumsum_trick(x, geom_feats, ranks)n else:n x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks)nn # griddify (B x C x Z x X x Y)n # 构建BEV特征,此时Z还没有被压缩。将geom特征索引对应填充融合后的x特征n final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device)n final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = xnn # collapse Z 压缩Z维度,变成BEV特征n final = torch.cat(final.unbind(dim=2), 1)nn return final
BEV特征编码
这一部分就比较简单了,BEV特征其实就变成了一个2维特征,按照通常的2D卷积编码即可。
class BevEncode(nn.Module):n def __init__(self, inC, outC):n super(BevEncode, self).__init__()nn trunk = resnet18(pretrained=False, zero_init_residual=True)n self.conv1 = nn.Conv2d(inC, 64, kernel_size=7, stride=2, padding=3,n bias=False)n self.bn1 = trunk.bn1n self.relu = trunk.relunn self.layer1 = trunk.layer1n self.layer2 = trunk.layer2n self.layer3 = trunk.layer3nn self.up1 = Up(64+256, 256, scale_factor=4)n self.up2 = nn.Sequential(n nn.Upsample(scale_factor=2, mode='bilinear',n align_corners=True),n nn.Conv2d(256, 128, kernel_size=3, padding=1, bias=False),n nn.BatchNorm2d(128),n nn.ReLU(inplace=True),n nn.Conv2d(128, outC, kernel_size=1, padding=0),n )nn def forward(self, x):n x = self.conv1(x)n x = self.bn1(x)n x = self.relu(x)nn x1 = self.layer1(x)n x = self.layer2(x1)n x = self.layer3(x)nn x = self.up1(x, x1)n x = self.up2(x)nn return x
得到BEV特征后,后面的过程如果需要做3D目标检测,则跟踪生成的BEV空间的gt监督BEV空间预测的目标。
小结
总的来说这篇paper开创了,在不采用直接深度估计的方式,利用环视输入来构建BEV特征,从而在BEV空间做目标检测和运动规划。是个非常不错的创新点,后续很多研究也是围绕该paper做改进和创新的。
当然,也有文章论证这种直接将深度和特征融合的方式并不能很好构建深度信息,Simple-BEV- What Really Matters for Multi-Sensor BEV Perception?文章有做对比实验说明这种隐式的深度构建方式和随机深度没有太大区别。
以上是个人对LSS读后笔记,有不对的地方欢迎指正。
参考文献
[1] Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
[2] Simple-BEV- What Really Matters for Multi-Sensor BEV Perception
问:2023年锅炉价格/多少钱?
上一篇:EMG伺服阀
下一篇:燃油燃气锅炉密封性好不好?






