
前言:NoSQL数据库四大家族 列存储 Hbase,键值(Key-Value)存储 Redis,图像存储 Neo4j,文档存储 MongoDB一、简介1.1 什么是neo4jNe
前言:NoSQL数据库四大家族 列存储 Hbase,键值(Key-Value)存储 Redis,图像存储 Neo4j,文档存储 MongoDB
一、简介
1.1 什么是neo4j
Neo4j是以原生图形数据库为核心,以更自然的连接状态存储和管理数据。 是用 Java 和 Scala 编写的,源代码可在GitHub上找到。
图数据库采用属性图方式,对遍历性能和操作运行时间都有好处。
1.1.1 什么是图数据库
图数据库是使用图数据结构存储数据,图数据结构由可以通过关系连接的节点组成,如下图
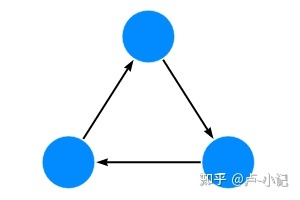
Neo4j 属性图数据库模型包括: - 节点描述域的实体(离散对象)。 - 节点可以有零个或多个标签来定义(分类)它们是什么类型的节点。 - 关系描述了源节点和目标节点之间的连接。 - 关系总是有一个方向(一个方向)。 - 关系必须有一个类型(一种类型)来定义(分类)它们是什么类型的关系。 - 节点和关系可以具有进一步描述它们的属性(键值对)
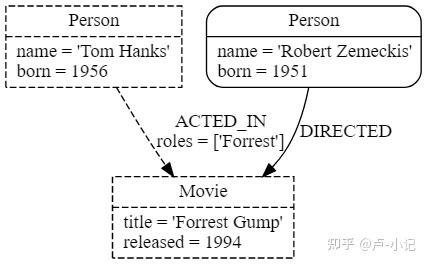
我们可以从上图来认识下图数据库模型 - 节点:三个方框 - 标签:方框上半部分 - 节点属性:方框下半部分 - 关系:虚线和实线 - 关系类型:ACTED_IN和DIRECTED - 关系属性:roles=['Forrest']
1.2 neo4j历史
Neo4j 最初是作为嵌入式 Java 数据库创建的;这就是名称中的“4j”的来源。Neo4j 最初创建是为了解决创始人在构建内容管理系统 (CMS) 时遇到的一些问题,特别是围绕照片使用的一些权利和元数据。他们发现由于所有不同的连接和关系以及数据的丰富性,很难在关系数据库中表示。所以这就是 Neo4j 最初被创建的原因。
创始人也很快意识到,除了 CMS 应用程序中的这个嵌入式数据库之外,还有许多其他有趣的用例。所以 Neo4j 很快演变成一个更通用的系统迅速被使用在个性化推荐,以及处理物流和路线、网络拓扑图等地方.
1.3为什么要使用neo4j
我们生活在一个互联的世界中,无论是社交网络、支付网络还是道路网络,您都会发现一切都是相互关联的关系图
传统数据库数据格式很难处理数据之前的关联关系,就算有主键关联,随着深度加深难度指数上升,而因为neo4j使用的是图数据库的方式存储,意味着我们不需要使用特殊属性(例如外键)或带外处理(例如 map-reduce)来推断实体之间的连接。通过将节点和关系组装成连接的结构,图数据库使我们能够构建简单而复杂的模型,这些模型紧密地映射到我们的问题域。
在neo4j官网中有一份测评报告,查找用户好友及好友的好友,包含100万数据的,mysql及neo4j效率对比如下
| 层级 | Execution Time – MySQL | Execution Time–Neo4j |
|---|---|---|
| 2 | 0.016 | 0.010 |
| 3 | 30.267 | 0.168 |
| 4 | 1,543.505 | 1.359 |
| 5 | Not Finished in 1 Hour | 2.132 |
上述结果可以看出简单的好友查询neo4j比mysql快60%,查朋友的朋友时,neo4j效率比mysql高180倍,深度为3时,neo4j效率比mysql高1135倍,深度为五时mysql超时
二、neo4j安装
1、官网下载合适版本,下载链接 4.0版本以上就需要jdk11支持了
2、解压安装包
3、bin目录下打开cmd
4、neo4j.bat install-service安装neo4j服务
5、neo4j.bat start启动
6、使用浏览器neo4j http://127.0.0.1:7474/
默认的账号是 neo4j 密码 neo4j 这里第一次登录的话会要求修改密码
至此我们就可以正常使用neo4j了
我们在使用过程中需要学习Cypher图形查询语言
三、cypher语言学习
3.1 什么是Cypher语言
Cypher 是一种声明式图查询语言,允许对图进行富有表现力和高效的查询、更新和管理。由于它与其他语言的相似性和直观性,它是迄今为止最容易学习的图形语言。
3.2 学习Cypher语言
3.2.1 cypher语法介绍
我们已经知道cypher是用来查询neo4j图数据中的数据,所以我们可以结合一个图数据来认识cypher语法
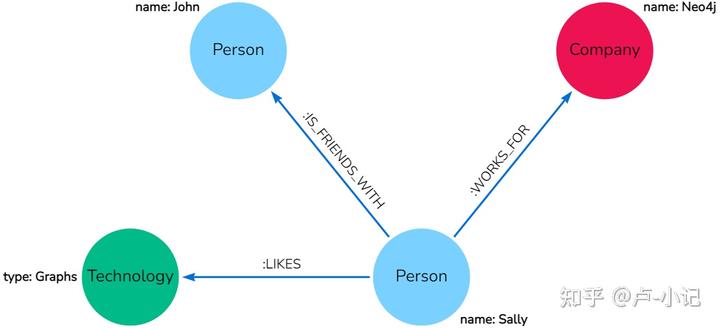
从上图按照我们学习的neo4j基础概念可以知道以下信息:
sally喜欢图表技术,和John是朋友,为Neo4j工作
我们通过基础概念学习已经知道图数据是包括:节点(节点标签、节点属性)、关系(关系类型、关系属性),我们接下来就需要使用Cypher将这些表示出来
1. 节点表示
Cypher 中的节点,是使用括号将节点括起来,例如(node),括号看起来与可视化表示用于我们数据模型中节点的圆圈的相似之处。节点的任何信息都可以卸载括里面包括:节点变量、节点标签、节点属性
- 节点变量 如果我们查询到一个节点,然后想在查询后返回节点,我们就需要定义一个变量,就如果我们在java调数据库查到数据需要对象接收一样,如果不定义就无法在后续使用数据
- 节点标签 上述图中我们可以看到每个节点都有标签,如果我们想筛选指定标签的数据或给节点创建标签,我们可以指定节点标签,如图中的Person,Technology、 和Company
- 节点属性 如图中的节点属性,如果我们想要按照属性筛选或给节点创建属性,可以指定属性
示例:
(p:Person {name: 'Sally'})n(:Person {name: 'Sally'})
p为变量,Person为标签,{name: 'Sally'}为属性
2. 关系表示
为了充分利用图数据库的功能,我们还需要表达节点之间的关系。关系在 Cypher 中使用箭头-->或<--两个节点之间表示,语法看起来像在表示中连接我们的节点的箭头和线。无向关系表示为没有箭头,只有两个破折号--,虽然插入必须有方向,但是在查询的时候如果不知道方向也是可以不指定,这意味着可以在任一方向上遍历关系
有关关系的信息,我们可以使用【】中括号编写,有关关系的任何信息都可以写在中括号中,如下述示例
(p:Person)-[rel:LIKES {type:'Graphs'}]->(t:Technology) n(p:Person)<-[rel:LIKES {type: 'Graphs'}]-(t:Technology) n(p:Person)-[rel:LIKES {type: 'Graphs'}]-(t:Technology)
我们也可以将一个sql赋值一个变量,可以在语句其他地方使用
sql = (p:Person)-[rel:LIKES {type: 'Graphs'}]->(t:Technology)
3.2.2 Cypher语法实践
我们已经知道如何通过Cypher表示图数据中的节点、关系、属性等信息,但是缺少一些关键字来告诉我们是要做什么动作,比如创建还是查询,见下列表格
| S.No | Cypher关键字 | 作用 |
|---|---|---|
| 1 | CREATE 创建 | 创建节点,关系和属性 |
| 2 | MATCH 匹配 | 检索有关节点,关系和属性数据 |
| 3 | RETURN 返回 | 返回查询结果 |
| 4 | WHERE 条件 | 提供条件过滤检索MATCH数据 |
| 5 | DELETE 删除 | 删除节点和关系 |
| 6 | REMOVE 移除 | 删除节点和关系的属性 |
| 7 | SET 设置 | 添加或更新标签 |
| 8 | ORDER BY 排序 | 对结果排序 |
| 9 | SKIP LIMIT 分页 | 分页 |
| 10 | DISTINCT 排重 | 排重 |
接下来我们要使用这些关键字和我们学习的基础语法在neo4j中进行增删改查
创建操作
创建节点
#创建单个节点nCREATE (n)n#创建多个节点nCREATE (n), (m)n#创建带有单个标签的节点nCREATE (n:Person)n#创建带有多个标签的节点nCREATE (n:Person:Swedish)n#创建带有标签和属性的节点并返回nCREATE (n:Person {name: 'Andy', title: 'Developer'}) return n.name,n.titlen#创建一个电影节点nCREATE (m:Movie {title:'测试电影'})
创建关系
#创建已知节点创建关系,并设置属性nmatch (p:Person),(m:Movie)nwhere p.name = 'Andy' and p.title = 'Developer' and m.title = '测试电影'ncreate (p)-[r:ACTED_IN {year:1980}]->(m)nreturn p,r,mn#创建新的节点并创建关系ncreate (p:Person {name:"Jry"})-[r:WORK_FOR]->(m:michael{name:'Mich'})nreturn p,r,m
创建完整链路
#创建完整链路ncreate p = (Person {name:"Tom"})-[:WORK_FOR]->(michael{name:'Michael'})nreturn p
MERGE操作
MERGE操作会先进行查询如果未查询到会进行新建操作
#新建一个张三节点nmerge (p:Person {name:'张三'})nreturn pn#还是新建张三并进行属性匹配,由于属性不完全匹配还是新增操作,可以看到id不同nmerge (p:Person {name:'张三',height:185})nreturn pn#匹配存在的节点nmerge (p:Person {name:'张三',height:185})nreturn pn#以现有节点属性去匹配新增节点nMATCH (person:Person)MERGE (city:City {name: person.bornIn})nRETURN person.name, person.bornIn, cityn#创建节点时设置额外属性nMERGE (keanu:Person {name: '李四'})nON CREATEn SET keanu.created = timestamp()nRETURN keanu.name, keanu.createdn#找到节点时设置额外属性nMERGE (person:Person {name:'张三'})nON MATCHn SET person.found = truenRETURN person.name, person.foundn#ON CREATE/ON MATCH可以一起使用n#关系不存在创建关系nMATCHn (charlie:Person {name: '张三'}),n (wallStreet:Movie {title: '测试电影'})nMERGE (charlie)-[r:ACTED_IN]->(wallStreet)nRETURN charlie.name, type(r), wallStreet.title
更多merge操作参考官方文档
SET操作
set操作可以用来做更新操作
新增属性
#设置属性nMATCH (n {name: '张三'})nSET n.surname = '胖墩'nRETURN n.name, n.surnamen#使用case-when设置属性nMATCH (n {name: '张三'})nSET (CASE WHEN n.height = 185 THEN n END).worksIn = '工厂'nRETURN n.name, n.worksIn
更新属性
MATCH (n {name: '张三'})nSET n.height = toString(n.height)nRETURN n.name, n.height
删除属性
#删除单个属性nMATCH (n {name: '张三'})nSET n.height = nullnRETURN n.name, n.heightn#删除所有属性nMATCH (p {name: 'Jry'})nSET p = {}nRETURN p.name
DELETE操作
delete可以进行删除节点操作,前提是需要将节点上的关系清除
MATCH (n:Person {name: '李四'})nDELETE nn#当数据量不大,我们想清除所有数据nMATCH (n)nDETACH DELETE nn#删除节点及所有关系nMATCH (n {name: 'Andy'})nDETACH DELETE nn#只删除关系nMATCH (n {name: 'Tom'})-[r:KNOWS]->()nDELETE r
REMOVE操作
remove主要用来删除属性和标签
Neo4j 不允许存储null在属性中。相反,如果不存在值,则该属性不存在
#删除属性nMATCH (a {name: '张三'})nREMOVE a.heightnRETURN a.name, a.heightn#删除标签nMATCH (n {name: 'Tom'})nREMOVE n:PersonnRETURN n.name, labels(n)n#删除多个标签nMATCH (n {name: 'Tom'})nREMOVE n:Person:MovienRETURN n.name, labels(n)
MATCH查询操作
要进行查询操作,我们首先初始化一批数据
在安装完成neo4j后,可以直接使用 http://127.0.0.1:7474/页面中的示例数据来初始化数据
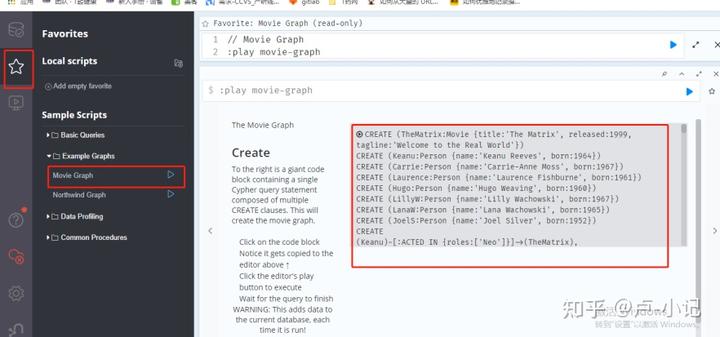
执行后得到下面结果:
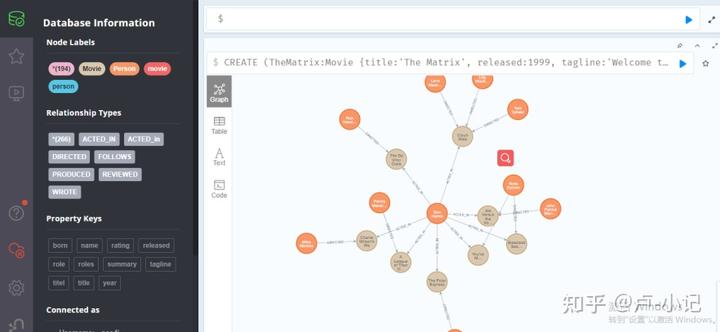
我们基于这些数据进行后续的查询操作
节点查询
#查询所有节点nMATCH (n)nRETURN nn#根据标签查询nmatch (m:Movie)nreturn mn#和Lana Wachowski相关的数据 --表示相关,无视关系类型和方向nMATCH (director {name: 'Lana Wachowski'})--(movie)nRETURN movie.title
关系查询
#查看和Lana Wachowski属于》关系的数据nMATCH (:Person {name: 'Lana Wachowski'})-->(movie)nRETURN movie.titlen#关系匹配nMATCH (wallstreet:Movie {title: 'A Few Good Men'})<-[r:ACTED_IN]-(actor)nRETURN actor.name,rn#多关系匹配nMATCH (wallstreet:Movie {title: 'A Few Good Men'})<-[:ACTED_IN|DIRECTED]-(actor)nRETURN actor.namen#多重关系匹配nmatch (p:Person {name:'Keanu Reeves'})-[r:ACTED_IN]->(m:Movie)<-[r1:DIRECTED]-(director:Person)nreturn m.title, director.namen#可变长度关系匹配n#如下查看和Keanu Reeves相关的ACTED_IN关系节点,路径长度为1-3nmatch (p:Person {name:'Keanu Reeves'})-[r:ACTED_IN*1..3]->(m:Movie)nreturn m
最短路径
#查看两人节点数不超过15个的最短路径nmatch n(p:Person {name:'Keanu Reeves'}),n(p1:Person {name:'Lilly Wachowski'}),ns = shortestPath((p)-[*..15]-(p1))nreturn sn#路径过滤,查找路径时不考虑PRODUCED关系nmatch n(p:Person {name:'Keanu Reeves'}),n(p1:Person {name:'Lilly Wachowski'}),ns = shortestPath((p)-[*..10]-(p1))nWHERE none(r IN relationships(s) WHERE type(r) = 'PRODUCED')nreturn s
ID查找
#id查找nMATCH (n)nWHERE id(n) = 0nRETURN nn#关系id查找nMATCH (a)-[r]-(b)nWHERE id(r) = 0nRETURN a, bn#多ID匹配nMATCH (n)nWHERE id(n) IN [0, 3, 5]nRETURN n
3.2.3cypher高级功能
字符串函数
left函数
left函数相当于从左侧开始截取字符串
RETURN left('hello', 3)
Right函数
right函数相当于从右侧开始截取字符串
RETURN right('hello', 3)
ITrim函数
ITrim函数主要去除前导空格
RETURN lTrim(' hello')n#返回'hello'
rTrim函数
ITrim函数主要去除后导空格
RETURN rTrim('hello ')n#返回'hello'
replace函数
replace函数替换目标字符串
RETURN replace("hello", "l", "w")n#返回"hewwo"
split函数
split函数指定符号拆分字符串
RETURN split('one,two', ',')n#返回["one","two"]
更多字符串函数参考https://neo4j.com/docs/cypher-manual/current/functions/string/
聚合函数
avg函数
该函数avg()返回一组数值的平均值
MATCH (n:Person)nRETURN avg(n.born)
collect函数
该函数collect()返回一个聚合列表,其中包含表达式返回的值。任何null值都将被忽略,并且不会添加到列表中。
MATCH (n:Person)nRETURN collect(n.born)
count函数
该函数count(*)可用于返回节点数
#节点求数量nMATCH (n {name: 'Keanu Reeves'})-->(x)nRETURN labels(n), n.born, count(*)n#关系分组求数量nMATCH (n {name: 'Keanu Reeves'})-[r]->(x)nRETURN type(r), count(*)
max/min函数
该函数max/min返回一组值中的最大/小值。字符串默认低于0
#最大nUNWIND [1, 'a', null, 0.2, 'b', '1', '99'] AS valnRETURN max(val)n#最小nUNWIND [1, 'a', null, 0.2, 'b', '1', '99'] AS valnRETURN min(val)
更多聚合函数参考https://neo4j.com/docs/cypher-manual/current/functions/aggregating/#functions-max
shortestPath 函数
返回最短路径
MATCH p=shortestPath((person:Person {name:"Keanu Reeves"})-[*]-(person2:Personn{name:"Lilly Wachowski"}) ) RETURN length(p), nodes(p)
四、事务
为了保持数据的完整性和保证良好的事务行为,Neo4j也支持ACID特性 。
注意:
(1)所有对Neo4j数据库的数据修改操作都必须封装在事务里。
(2)默认的isolation level是READ_COMMITTED
(3)死锁保护已经内置到核心事务管理 。 (Neo4j会在死锁发生之前检测死锁并抛出异常。在异常抛出之前,事务会被标志为回滚。当事务结束时,事务会释放它所持有的锁,则该事务的锁所引起的死锁也就是解除,其他事务就可以继续执行。当用户需要时,抛出异常的事务可以尝试重新执行)
(4)除特别说明,Neo4j的API的操作都是线程安全的,Neo4j数据库的操作也就没有必要使用外部的同步方法。
五、索引
Neo4j CQL支持节点或关系属性上的索引,以提高应用程序的性能。
可以为具有相同标签名称的属性上创建索引。
可以在MATCH或WHERE等运算符上使用这些索引列来改进CQL 的执行
创建索引
#创建节点单一属性索引nCREATE INDEX ON:Person (name)n#创建复合索引nCREATE INDEX ON:Person (name,born)
查看索引
call db.indexes
删除索引
DROP INDEX ON :Person(name)
六、约束
作用 - 避免重复记录。 - 强制执行数据完整性规则
唯一节点属性约束
唯一属性约束确保属性值对于具有特定标签的所有节点都是唯一的。对于多个属性的唯一属性约束,属性值的组合是唯一的。
唯一约束不要求所有节点都具有列出的属性的唯一值——没有对应属性的节点不受此规则的约束
#创建唯一节点属性约束nCREATE CONSTRAINT ON (person:Person) ASSERT person.name IS UNIQUEn#删除唯一节点属性约束nDROP CONSTRAINT ON (cc:Person) ASSERT cc.name IS UNIQUn#查看约束ncall db.constraints
六、Spring boot整合neo4j
1、增加依赖
<dependency>n <groupId>org.springframework.boot</groupId>n <artifactId>spring-boot-starter-data-neo4j</artifactId>n</dependency>n<dependency>n <groupId>org.neo4j</groupId>n <artifactId>neo4j-ogm-bolt-driver</artifactId>n</dependency>
2、增加配置
spring:n data:n neo4j:n username: neo4jn password: 123456n uri: bolt://127.0.0.1:7687
3、增加节点实例
@NodeEntityn@Datanpublic class Person implements Serializable {n @Idn @GeneratedValuen private Long id;n @Property("cid")n private int pid;n @Propertyn private String name;n @Relationship(type = "Friends",direction = Relationship.INCOMING)n private Set<Person> relationPersons;n}
4、增加dao类
@Repositorynpublic interface PersonDao extends Neo4jRepository<Person,Long> {n @Query("match(p:Person) where p.born > {0} return p")n List<Person> personList(Integer born);n @Query("MATCH p=shortestPath((person:Person {name:{0}})-[*1..4]- (person2:Person {name:{1}}) ) RETURN p")n List<Person> shortestPath(String startName,String endName);n}
5、增加服务类
@Servicenpublic class PersonService {n @Autowiredn private PersonDao personDao;nn public List<Person> personList(Integer born){n return personDao.personList(born);n }n public Person save(Person person){n return personDao.save(person);n }nn public List<Person> shortestPath(String startName, String endName){n return personDao.shortestPath(startName,endName);n }n}
6、测试类
@SpringBootApplicationnpublic class Neo4jSpringbootDemoApplication {nn public static void main(String[] args) {n ApplicationContext app =n SpringApplication.run(Neo4jSpringbootDemoApplication.class,args);n PersonService personService =n app.getBean(PersonService.class);n List<Person> datas = personService.personList(1980);n System.out.println(datas);n System.out.println(personService.shortestPath("Bill Pullman","Tom Hanks"));n }nn}
以上内容就是neo4j的基础概念和基础使用
neo4j的官方文档内容非常详细,大家想深入了解可以官网查看
大家有更好的观点可以评论或私信讨论
问:2023年锅炉价格/多少钱?
上一篇:每天都离不开的厨房家电清单
下一篇:机加工三好四管






