
一、Tage预测器前身TAGE分支预测是综合O-GEHL分支预测和PPM-like分支预测所设计的分支预测算法。由base predictor T0,和一序列(par
一、Tage预测器前身
TAGE分支预测是综合O-GEHL分支预测和PPM-like分支预测所设计的分支预测算法。由base predictor T0,和一序列(partially)tagged predictor components Ti组成,tagged predictor components Ti所采用索引历史长度是不同的,成几何长度关系。
而TAGE,就像他名字写的那样,有两个特征让他的accuracy很高:
- TA(Taged)
目前分支预测的索引一般为PC或者PC和global history的xor,出于存储效率考虑,只有一部分会用于索引,会有aliasing。这个时候如果把多余的PC存起来做tag,就能更好地比对出哪些是真match,哪些是aliasing,有助于选取到真正对应的entry。
2. GE(Geometrical)
主流观点认为一般global history match的长度越多,预测就越准确。所以TAGE选取了几何增长的history长度,如32,64,128,256。原则上,每次优先选取最长的match做预测。当然也有一些简单地branch可能不需要那么长,短的就好。TAGE的userful counter 就发挥了作用。如果短的history predict的效果就很好,就会通过userful counter 反映出来。
1. O-GEHL预测器
TAGE预测器比O-GEHL预测器的硬件复杂度更低(不使用动态历史长度拟合,更短的全局历史)。同时,在相同的存储预算和相同的预测器复杂度下,TAGE预测器优于O-GEHL预测器。

(1)结构
- 由多个预测表组成,每个表由PC和不同长度的历史和指令地址共同索引。其中历史长度呈几何级数
- 最终的预测通过加法树得出。
- 在GEHL的基础上增加动态历史长度自适应和阈值调整
(2)预测
预测是通过将预测表上读取的预测相加来计算的,其中M是表项的个数,C(i)是每个表项的有符号饱和计数器,假设计数器的宽度是两位,那么C(i)的最大值是1,最小值是-2。
S = M2 +
C(i) ------ 当S>0时则预测跳转,当S<0则预测不跳转
(3)更新
GEHL预测器更新策略来源于感知器预测器更新策略,GEHL预测器仅在预测错误或计算的和S的绝对值小于阈值( 
if (( p! = Out ) or ( |S| <
for each i in parallel
if Out then C(i) = C(i) + 1 else C(i) = C(i) - 1
(4)自适应阈值
且对于大多数benchmark,阈值的质量与错误预测的更新次数 

基于此,采用一个7-bit 饱和计数器TC,提出如下阈值自适应算法:
if((p!=out))n{n TC=TC+1;n if(TC==SaturatedPositive)n θ=θ+1;TC=0;n}nif((p==out)&(|s|≤θ))n{n TC=TC-1;n if(TC==SaturatedNegative)n θ=θ-1;TC=0;n}n
(5)动态历史长度自适应
基于对表 T7 上更新时的混叠率的粗略估计,采取动态选择历史长度以索引预测器的算法。
例如,一个O-GEHL有8个表,11种历史长度,使其中三个表对应两种可用的历史长度,即T2:L(2),L(8);T4:L(4),L(9);T6:L(6),L(10)。表 T7 是除了 L(8)、L(9) 和 L(10) 以外使用最长历史间隔的预测器组件。 直观地说,如果表 T7 出现高度混叠,则应在表 2、4 和 6 上使用短历史; 另一方面,如果表 T7 遇到低度混叠,则应使用长历史记录。
动态估计T7的混叠率:在T7的某些项上增加 tag-bit,用一个单独的9-bit 饱和计数器AC
在预测器更新时,tag-bit 记录分支pc的一位(最低位),然后执行以下算法:
if((p!=out)&(|S|≤θ))n{n if((PC&1)==Tag[indexT[7]])n AC++;n else AC=AC-4;n if(AC==SaturatedPositive) Use Long Historiesn if(AC==SaturatedNegative) Use Short Historiesn Tag[indexT[7]]=(PC&1);n}n
当使用相同的(分支,历史)对对执行表 T7 中相应条目最后更新时,AC 递增。 当最后一次更新由另一个(分支,历史)对执行时,AC 减少 4。
2. PPM-like预测器
TAGE分支预测器直接源于PPM-like基于tag的分支预测器。
TAGE与PPK-like不同之处在于:
1.使用几何历史长度序列
2.一种新的高效预测器更新算法

(1)结构
由多个banks组成。
第一个bank是一个基础预测器(一个双模态预测器),单由PC索引,包括3位的饱和计数器和1位的m bit,m表示meta-predictor即元预测器。
其余banks由PC和不同长度的全局历史位共同索引,每一项包括3位饱和计数器、8位tag和1位的u bit。u bit表示useful entry,
其余banks中PC和全局历史一方面hash确定索引bank中的哪一项(图中的10bit),另一方面hash计算tag,看计算的tag和索引项中的8-bit tag是否匹配 。
当全局历史位超出索引位长度时,对全局历史位进行折叠,称为历史折叠(history folded)。
(2)预测
预测时同时访问所有预测器,如果其余banks中由tag匹配,则使用tag匹配的banks进行预测,如果有多个tag命中,则采用历史长度最长的bank的预测;如果没有匹配的tag,则使用基础预测器预测。
(3)更新

预测正确:则不必分配新项。
预测错误:bank X最终提供预测,若X≤3且预测错误,则在banks n>X中分配一项或多项。取bank X+1 到 bank 4的对应项的u bit, 替换其中u=0的项,若无,从中任意选取一项替换。
填充规则:tag填充该bank哈希出的8bit tag;u填充0;ctr填充100或011,选择规则如下:
读取bank0对应项的m:
若为1,看bank X预测结果是taken还是not taken,taken填充100,not taken填充011。
若为0,看bank 0预测结果是taken还是not taken,taken填充100,not taken填充011。
(4)更新原理
更新m-bit和u-bit原理:
若最终预测不同于双模态预测,有如下两种情况:
1. 最终预测正确,双模态预测错误:u-set,m-set
此时说明当前分支与当前全局历史相关性强,提供最终预测的bank有用,故其u-bit set;
m-bit set表示当为该分支分支新项时其饱和计数器应初始化为最终预测(正确的预测)。
2. 最终预测错误,双模态预测正确:u-reset,m-reset
此时说明提供最终预测的bank无用,故其u-bit reset;
当前分支与当前全局历史相关性差,m-bit reset 表示为该分支分配新项时其饱和计数器应初始化为双模态计数器的结果(正确的预测)。
二、Tage预测基本原理
1. Tage预测原理
TAGE分支预测器直接源于PPM-like基于tag的分支预测器。由base predictor T0,和一序列(partially)tagged predictor components Ti组成,tagged predictor components Ti所采用索引历史长度是不同的,成几何长度关系:

其中:
base predictor T0就是简单的PC索引的2-bit饱和计数器。
tagged predictor components Ti 由3 bit的signed ctr(有符号计数器),tag,以及2bit的unsigned useful counter u组成。
其中:
pred:表示的是ctr项,用来预测是否进行跳转
tag:用来保存pc和跳转历史哈希之后的结果,以便预测时判断是否命中,一般在7-14可以取得好的效果,使用10或许是一个很好的权衡,同时,标签的宽度应该(稍微)随着历史长度的增加而增加:在使用最长历史的表上,错误的匹配更有害。
u:表示这个components 的置信度如何
预测计算方法跟PPM-like相似,若tag命中则取其中历史长度最长的component的预测结果,若未命中,则取base predictor的预测结果。
一些有用的概念:
provider component: tag命中则取其中历史长度最长的conponent,若无,即base predictor。
alternate component: 次一级tag命中的component,若无,即base predictor。
2. Tage更新策略
(1)更新useful counter u:
if provider pred != altpred, 更新provider component中对应项的u(置信度)(即预测正确+1,预测错误-1,在边界则不变)
因为当altpred 和 provider 预测相同时,说明没有必要用历史更长的provider,用前者预测就足够,因此不增加其有用计数器;当二者不同且后者正确时,说明provider是有用且必要的,因此增加其有用计数器。
此外,周期性重置所有的u为0,先重置高位,再重置低位。文中周期重置为256K branch(?)。
(2)预测成功或失败时,更新ctr(counter)
预测正确时:更新provider component的ctr,当预测可信度较低时,也会更新alter提供者。
预测错误时:
1. 更新provider component的ctr
2. 分配新项(至多分配一项):
(1)如果provider不是最长的历史项,则需在比提供预测组件历史更长的且u-bit为空的组件中分配新项。
若provider component 为 Ti,读T(i+1)至T(M-1)的对应项的u,若有u = 0,替换其中最低历史长度的条目(条目)。若无,这些u = u -1。
(2)如果有两个组件Tj和Tk(j < k)都可被分配((i.e., 

(3)初始化条目:填充的ctr为weak correct, u为0。
当最长的历史命中条目是一个新分配的条目时,使用altpred作为预测比normal预测更有效。如果一个条目的有用计数器为空,并且它的预测计数器很弱(0或-1),我们就认为它是新分配的,我们的实验表明,该属性对于应用程序是全局的,可以通过单个4位计数器动态监控。
u-bit策略:在分配新项时,动态监控预测失误后尝试分配新项的成功和失败次数,这种监控通过一个名为TICK的计数器实现。预测失误时,相关项的u-bit可能递会减,而递减的概率随着TICK计数器值的增加而增加。
当tag匹配的项的置信度计数器ctr为0时,altpred有时比正常预测更准确。因此在实现中使用一个4-bit计数器useAltCtr,动态决定是否在最长历史匹配结果信心不足时使用备选预测。在实现中处于时序考虑,始终用基预测表的结果作为备选预测,这带来的准确率损失很小。
备选预测逻辑的具体实现如下:
ProviderUnconf表示最长历史匹配结果的信心不足。当provider对应的ctr值为0b100、0b011时,说明最长历史匹配结果的信心很足,此时providerUnconf为false;当provider对应的ctr值为0b01、0b10时,说明最长历史匹配结果的信心不足,此时providerUnconf为true。
3. 更新策略的基本原理
首先,更新策略的设计目的是最大限度地减少一次分支出现所引起的扰动。
为了最小化单个(分支,历史)对的占用空间,在错误预测的情况下,最多分配一个带标记的条目。
要分配的条目的选择是通过有用的计数器来管理的,我们管理有用计数器有两个目标,只有当自上次分配条目以来有一些正收益时,u的值才能为正:
- 保证最近有用的条目不会被重新分配
2. 通过在条目未被选中时减少u计数器和其优雅的重置,我们尝试模拟伪最近最少策略
有用的计数器u被设置为强而无用: 在条目有效地帮助提供正确的预测之前,它是下一个替换的自然目标
有时需要多次访问Tage预测表,即在预测时读取所有预测器表,在提交时读取所有预测器表,在更新时写入(最多)两个预测器表,但是,可以避免在提交时进行读取。预测时可用的少量信息(提供组件的编号、提供组件的ctr和u值以及所有u计数器的0值),以便被检查。
4. 一些问题
- 为什么要用不同长度的历史?
既适用于有较长历史的分支可以利用足够多的历史,又可以为历史较短的分支或等待 warm up 的过程提供预测,当没有较长历史时仍可以采用已有的历史进行预测
- 为什么用部分标记匹配而不是加法树?
对于使用几何序列历史长度的预测器,部分标记匹配比加法树更具成本效益。
- 为什么要及时更新预测表?
在处理器中,硬件预测器表在指令退休时更新,以避免被错误路径污染。每个在正确路径上的分支访问3次预测期表:预测时读、退休时读、退休时写,如此大量的访问可能会导致非常昂贵的分支预测结构。

TAGE预测周期性的有规律的分支行为通常有效,即使周期长度横跨数百甚至数千个分支。但如果一个循环体内的控制流路径是不规律的,TAGE不能很好的预测循环退出分支。而循环预测器能够通过迭代的次数更加有效地跟踪循环,因此预测这些循环的退出分支非常有效。
- 为什么要用统计校正预测器?
一些应用上,一些分支行为与分支历史或路径相关性较弱,表现出一个统计上的预测偏向性。对于这些分支,相比TAGE,使用计数器捕捉统计偏向的方法更为有效。
- 为什么要使用局部历史?
在一些应用中,有一些分支使用局部历史比使用全局历史能够进行更好的预测。将SC中的全局历史替换为局部历史提供了一种平稳地将TAGE和局部预测器结合起来的方法。
三、ITTage预测器
ITTAGE预测器的原理主要用于预测间接跳转指令。
与Tage相似,predictor有一个无标记的基础预测器IT0,它负责提供默认预测和一组(部分)标记的预测器组件。
标记表上的条目由部分标记tag、跳转目标Targ、置信位c和2位有用计数器u组成,在TAGE中表示预测的计数器被完整的目标地址Targ加上置信位c所取代,以获得预测器上的一些迟滞。
主要的预测原理图如下:
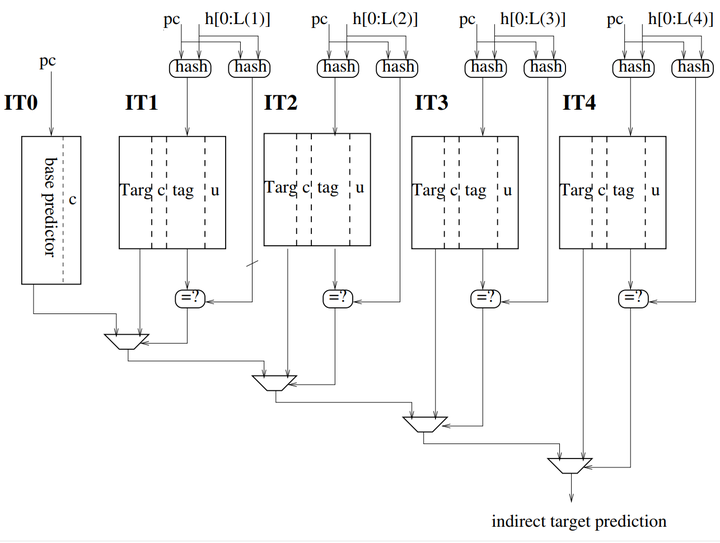
预测选择算法直接继承自TAGE预测器。预测器更新算法也继承自TAGE更新算法。
如果发生命中,目标替换在基础预测器和标记组件上,但错误预测是通过单个置信位控制的。
四、COTTAGE预测器
COTTAGE预测器实现了实现了TAGE预测器和ITTAGE预测器的组合,存储条件跳转预测和间接跳转预测,同时标签和索引计算逻辑也是共享的。在每个循环中,在同一行上读取条件分支预测和间接跳转预测。
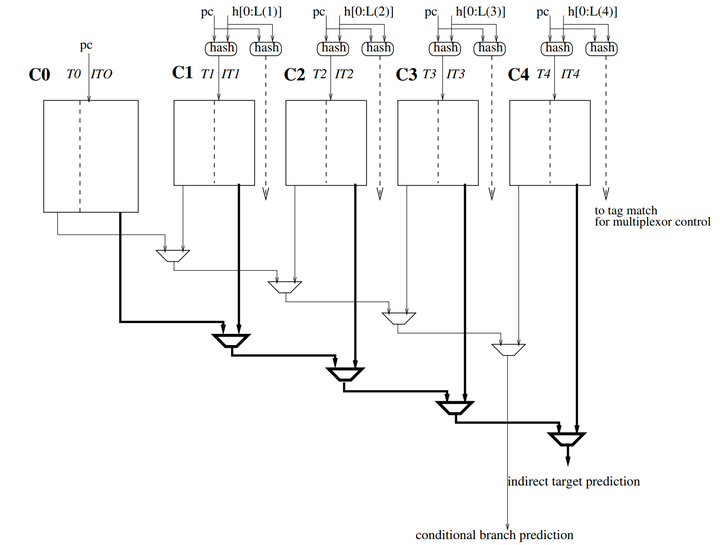
在高端超标量处理器上,所有的预测结构(条件分支预测器、间接跳转预测器、返回堆栈、BTB)都必须投机性地访问。TAGE预测器和ITTAGE预测器结构的相似性允许在单个物理结构中重新组合条件分支预测器和间接跳转预测器。
为了成本效益,预测表必须实现更多的TAGE条目和ITTAGE条目。因此,预测表中的存储一个间接跳转预测和几个条件分支预测。省略了在每个COTTAGE组件出口选择正确的TAGE条目所需的多路复用器。
当考虑实现条件预测器和间接跳转预测器的预测成本时,COTTAGE预测器似乎是一种具有成本效益的解决方案:一个5分量的COTTAGE预测器在总共只使用5个存储表的情况下,对条件分支和间接跳转都提供了最先进的预测精度。
五、TAGE-SC预测器
TAGE在预测非常相关的分支时非常有效,TAGE未能预测有统计偏向的分支,例如只对一个方向有小偏差,但与历史路径没有强相关性的分支。TAGE-SC则负责预测具有统计偏向的条件分支指令并在该情形下反转 TAGE 预测器的结果。
统计校正的目的是检测不太可靠的预测并将其恢复,来自TAGE的预测以及分支信息(地址、全局历史、全局路径、局部历史)被呈现给统计校正预测器,其决定是否反转预测。
SC的预测算法依赖TAGE里面的是否有历史表hit的信号provided,以及provider的预测结果taken,从而来决定SC自己的预测。provided是使用SC预测的必要条件之一,provider的taken作为choose bit,选出SC最终的预测,这是因为SC在TAGE 预测结果不同的场景下可能有不同的预测。
统计校正预测器的一个相当有效的实现源自GEHL预测器,它具有4个逻辑表,用4个最短历史长度(0,6,10,17)作为主要的TAGE预测器,以及从TAGE预测器中流出的预测(已采取/未采取)。表项是1K的,每个6位的宽度,即总共24Kbit。

预测结果的计算方法是: 从统计校正表中读取的预测结果(集中化处理)之和加上TAGE中命中库输出结果(集中化处理)的8倍。所谓集中预测,我们指的是2*ctr+1策略。
如果统计校正器预测器不一致且总和的绝对值高于动态阈值,则还原TAGE预测。
动态阈值在运行时进行调整,以确保使用Statistical Corrector预测器是有益的。用于适应阈值的技术类似于动态适应GEHL预测器更新阈值的技术。
A. 对于32Kbits的预测器
使用校正过滤器,实际上是一个关联表,用于监控来自TAGE的错误预测,预测失误(PC和预测方向)以低概率存储在关联表中。命中校正过滤器时,如果某项指示以高置信度恢复预测,则预测被反转,但校正过滤器不会反转从TAGE流出的高置信度的分支。
64-entry 2-way纠正器用于13-bit entry (6-bit counter + 7-bit tag)。作为一种优化,来自TAGE的高置信度分支不会被校正滤波器反转,校正滤波器将总体错误预测率降低了约1.5%
B. 对于256Kbits的预测器
MGSC(multi-GEHL SC):由6个组件组成,1个偏置组件和5个GEHL-like组件。
返回堆栈相关分支历史:历史存储在与调用相同的返回堆栈中。在调用时,堆栈的顶部被复制到堆栈中新分配的条目上,在相关的返回之后,分支历史记录反映了调用之前执行的分支。这允许捕获在被调用函数的执行过程中可能丢失的一些相关性。
预测计算:统计校正预测器表上的预测结果之和的符号,加上GEHL表数量乘以方向(+1或-1)的两倍。(不确定是不是这么回事儿)
MGSC预测表使用动态阈值策略进行更新,使用一个PC索引的动态阈值表
六、香山处理器
1. 第一个周期(uFTB)
uBTB可以直接解决jal和jalr的跳转问题?
2. 第二个周期(FTB、TAGE)
(1)第一次更新时:
FTB:将最多(两条分支指令)的起始地址和结束地址保存到FTB中作为一个预测块。
情况1:如果一个预测块中只观测到一条分支指令,那么一个预测块的大小是32Byte
情况2:如果一个预测块中连续观测到两条分支指令/第一条是分支,第二条是直接跳转,那么预测块的大小是起始地址到终止地址之间的大小,终止地址是第二条分支或者跳转指令的地址
情况3:如果一个预测块中观测到第一条分支指令就是直接跳转,那么将直接跳转的地址作为终止地址
TAGE:将起始地址作为TAGE的PC,进行预测,这个PC可以指向的是一条指令,也可以是一块指令,这跟FTB的保存机制相关。
(2)预测时:
TAGE:⽤PC和分⽀历史寻址多个分⽀历史表,在多个命中的表项中优先挑选对应分⽀历史最⻓的
结果作为最终结果。表项内实际为⼀饱和计数器,最⾼位确定最终跳转⽅向。每个预测结果的meta
信息包含了预测所使⽤的预测表、当前的altpred结果等信息,会被写⼊FTQ中,更新时会复⽤这些
信息完成更新,其中tag利⽤update通道中更新⽤PC、分⽀历史计算,ctr更新时若在分配新表项,
则依据跳转与否更新为4或3,否则基于现有ctr值增减。
3. 第三个周期(RAS、TAGE-SC)
TAGE-SC:利⽤PC和分⽀历史寻址SC表,在TAGE给出的预测可信度不⾼时,反转其预测结果。SC同样
会将tageTakens、scUsed、scPreds、ctrs这类meta信息与预测结果⼀同传递写⼊到FTQ。在更新
时,将根据是否wrbypass选择原有ctr还是根据当前taken结果更新。此外全局的thresholds要在sc和
tage结果不⼀致时更新。







