
怪异的象再次出现。终于发现了端倪,是因为根节点的问题。只有根节点是报表的链条是有效的。形成树的要从根节点开始。254.得到了想
怪异的象再次出现。终于发现了端倪,是因为根节点的问题。只有根节点是报表的链条是有效的。形成树的要从根节点开始。
254.得到了想要的结果,但娶的不是我的意中人。想把ID扔掉,但到头来还是扔不掉。要自由,但脱不了ID锁链。要实现报表科目与会计科目重名,又要科目可以有空的下级科目,有下级科目的科目可以单独使用(有baby了又想单飞),要这些自由只能含泪戴上金箍儿,找富婆走上人生巅峰。内心是拒绝的,但是么得办法。OOO,Only you....这是一个悲伤的故事。
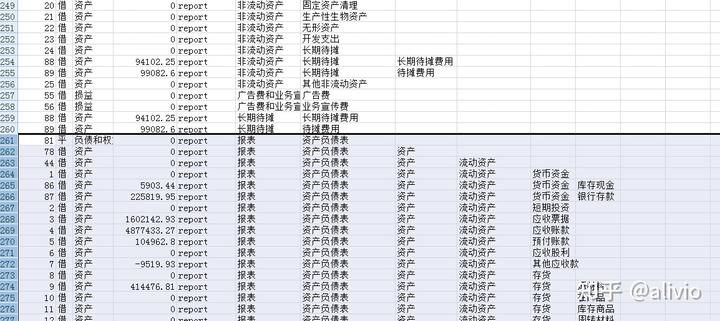
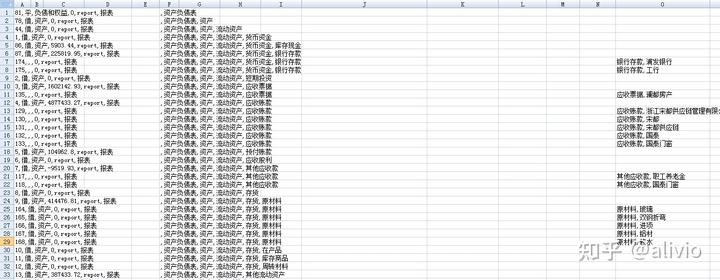
Dim offCols, exStr, offRows, Rcset_stage2nSub 提取目标科目()n'全部采用程序计算而不用表公式实现所有功能。大量表公式影响效率n'excel表的输出速度慢得不是一点点。noffCols = 3noffRows = 1nDim cnn As ObjectnDim Rcset As Object 'Rset竟然是保留字符号。nDim conncetStr, cnnStr, chainSheet, kemuStr, Rcset_1, Rcset_report, Rcset_2nSet cnn = CreateObject("ADODB.CONNECTION")nSet Rcset = CreateObject("ADODB.RECORDSET")nn'二级子节点,所有的父节点nSet Rcset_1 = CreateObject("ADODB.RECORDSET")nSet Rcset_2 = CreateObject("ADODB.RECORDSET")nSet Rcset_stage2 = CreateObject("ADODB.RECORDSET")nSet Rcset_report = CreateObject("ADODB.RECORDSET")nconncetStr = "Provider=Microsoft.ACE.OleDb.12.0;Extended Properties='Excel 12.0;HDR=YES';Data Source=" & ThisWorkbook.FullNamencnnStr = "Provider=Microsoft.ACE.OleDb.12.0;Extended Properties='Excel 12.0;HDR=YES'; Data Source=" & ThisWorkbook.FullNamencnn.Open cnnStrnts = "[期初余额_auto$A:M]"nSQL = "Select 序号,一级科目,二级科目,余额m,代码,方向,类别 from " & ts & " where 序号='ledger' and 一级科目<>''"nRcset_stage2.Open SQL, cnn, 3, 1nchainSheet = "链表图pro"nSQL_1 = "select distinct 一级科目 from " & ts & " where 序号='ledger'"nRcset_1.Open SQL_1, cnn, 3, 1n'全域内不允许重名就简单,但报表科目与会计科目之间会有重名。nSQL_report = "Select 序号,一级科目,二级科目,余额m,代码,方向,类别 from " & ts & " where 序号='report' and 一级科目<>''"nRcset_report.Open SQL_report, cnn, 3, 1nSQL_2 = "select distinct 一级科目 from " & ts & " where 序号='report'"nRcset_2.Open SQL_2, cnn, 3, 1nnnWith Worksheets(chainSheet)n .Selectn .Cells.Clearn '.[a1].CopyFromRecordset Rcset_reportn 'Do While Not Rcset_2.EOFn '神奇的树,找到根节点,循环都省了。n kemuStr = "报表"n exStr = "report," & kemuStrn parentToChain Rcset_report, "一级科目='" & kemuStr & "'", kemuStr, chainSheet, 1n 'Rcset_2.movenextn 'Loopn n If 0 Thenn Do While Not Rcset_1.EOFn kemuStr = Rcset_1.fields(0).Valuen exStr = "ledger," & kemuStrn parentToChain Rcset, "一级科目='" & kemuStr & "'", kemuStr, chainSheet, 1n Rcset_1.movenextn Loopn End Ifn ''''分裂变身n n .Columns("A:A").Selectn Selection.TextToColumns Destination:=.Range("A1"), DataType:=xlDelimited, _n TextQualifier:=xlDoubleQuote, ConsecutiveDelimiter:=False, Tab:=True, _n Semicolon:=False, Comma:=True, Space:=False, Other:=False, TrailingMinusNumbers:=Truen nEnd WithnEnd SubnFunction parentToChain(Rcset, fstr, kemuStr, chainSheet, stage)nDim moffset, mexnDim rstFilterednSet rstFiltered = CreateObject("ADODB.RECORDSET")nSet rstFiltered = Rcset.ClonenrstFiltered.Filter = fstrnmoffset = offColsnmex = exStrn'''如果rstFiltered.countn'Debug.Print rstFiltered.RecordCountnIf rstFiltered.RecordCount <= 0 Thenn'''n '二级火箭点火ledgern Debug.Print "二级火箭准备:", kemuStrn If stage = 1 Thenn kemuStr2 = kemuStrn parentToChain Rcset_stage2, "一级科目='" & kemuStr2 & "'", kemuStr2, chainSheet, 2n Elsen '二级结束,熄火n End IfnElsen nDo While Not rstFiltered.EOFn With Worksheets(chainSheet)n .Cells(offRows, 1) = rstFiltered.fields(4).Value & "," & rstFiltered.fields(5).Value & "," & rstFiltered.fields(6).Value & "," & rstFiltered.fields(3).Value & "," & exStr + "," & rstFiltered.fields(2).Valuen offRows = offRows + 1n If rstFiltered.fields(2).Value <> "" Thenn offCols = offCols + 1n exStr = exStr + "," & rstFiltered.fields(2).Valuen parentToChain rstFiltered, "一级科目='" & rstFiltered.fields(2).Value & "'", rstFiltered.fields(2).Value, chainSheet, stagen offCols = offCols - 1n exStr = mexn Else n End Ifn End Withn'parentToChain rstFilteredn rstFiltered.movenextnLoopnEnd IfnnEnd Function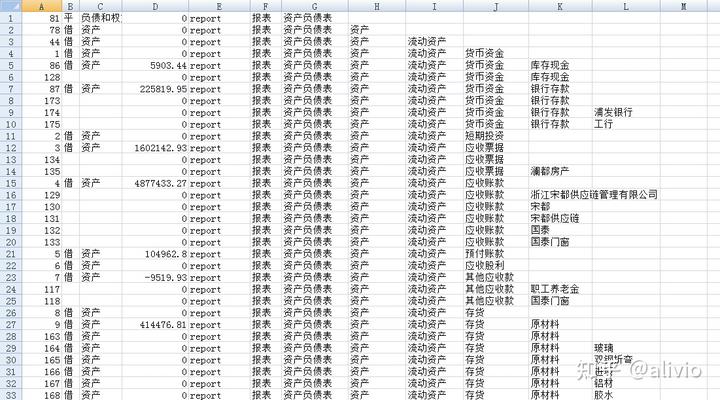
255.代码改得爹妈不认。简单的树,变成了分节状竹子。是否发明了一种新的数据结构叫做bamboo。各个节在空间上分开,每一层枝节双在空间上对齐,前一层的枝尖与后一层的枝根部有顺序链接,前一层枝尖(末)的节段值,是下一枝根的开始值。本来两段是连在一起的,但是为了stage,阶段字段的对齐,需要分开一段距离存储。这样的结构也可叫甘蔗结构。两个stage之间分开的距离就是甘蔗的一节。
难道我已经深入数据库对齐的峡谷盆地中了?是华容道、直布罗陀海峡、卡夫地峡谷、还是断肠崖绝情谷?
我为什么这么钟情干这个?看了自己都上火。sql 的group、sum功能难道那么诱人?直接弄个公式加加减减难道不香吗?中的什么邪。目前东西是搞出来了,但是速度是慢出天际。
Dim offCols, exStr, offRows, Rcset_stage2, Maxcols(256) As Integer, StageStr(256) As String, LeadStr(256) As StringnConst CoffsetColumns = 6nConst CoffsetRows = 1nConst MaxStage = 2nSub 提取目标科目()n'全部采用程序计算而不用表公式实现所有功能。大量表公式影响效率n'excel表的输出速度慢得不是一点点。nnMaxcols(0) = 1nfillMaxcolsnoffCols = 1noffRows = 1nDim cnn As ObjectnDim Rcset As Object 'Rset竟然是保留字符号。nDim conncetStr, cnnStr, chainSheet, kemuStr, Rcset_1, Rcset_reportnSet cnn = CreateObject("ADODB.CONNECTION")nSet Rcset = CreateObject("ADODB.RECORDSET")nn'二级子节点,所有的父节点nSet Rcset_1 = CreateObject("ADODB.RECORDSET")nSet Rcset_stage2 = CreateObject("ADODB.RECORDSET")nSet Rcset_report = CreateObject("ADODB.RECORDSET")nncnnStr = "Provider=Microsoft.ACE.OleDb.12.0;Extended Properties='Excel 12.0;HDR=YES'; Data Source=" & ThisWorkbook.FullNamencnn.Open cnnStrnts = "[期初余额_auto$A:M]"nchainSheet = "链表图pro"nnSQL = "Select 序号,一级科目,二级科目,余额m,代码,方向,类别 from " & ts & " where 序号='ledger' and 一级科目<>''"nRcset_stage2.Open SQL, cnn, 3, 1nnSQL_1 = "select distinct 一级科目 from " & ts & " where 序号='ledger'"nRcset_1.Open SQL_1, cnn, 3, 1n'全域内不允许重名就简单,但报表科目与会计科目之间会有重名。nSQL_report = "Select 序号,一级科目,二级科目,余额m,代码,方向,类别 from " & ts & " where 序号='report' and 一级科目<>''"nRcset_report.Open SQL_report, cnn, 3, 1nnWith Worksheets(chainSheet)n .Selectn .Cells.Clearn '.[a1].CopyFromRecordset Rcset_reportn 'Do While Not Rcset_2.EOFn '神奇的树,找到根节点,循环都省了。 n n kemuStr = "报表"n exStr = "report," & kemuStrn parentToChain Rcset_report, "一级科目='" & kemuStr & "'", kemuStr, chainSheet, 1n 'Rcset_2.movenextn 'Loopn n ''''分裂变身n If 0 Thenn .Columns("A:A").Selectn Selection.TextToColumns Destination:=.Range("A1"), DataType:=xlDelimited, _n TextQualifier:=xlDoubleQuote, ConsecutiveDelimiter:=False, Tab:=True, _n Semicolon:=False, Comma:=True, Space:=False, Other:=False, TrailingMinusNumbers:=Truen End IfnEnd WithnnEnd SubnnFunction parentToChain(Rcset, fstr, kemuStr, chainSheet, Stage)n'如果stage=0就是单体运行nDim moffset, mexnnDim rstFilterednSet rstFiltered = CreateObject("ADODB.RECORDSET")nSet rstFiltered = Rcset.Clonenn''''相当于一个functionnrstFiltered.Filter = fstrnnmoffset = offColsnnmex = StageStr(Stage)n'''如果rstFiltered.countn'Debug.Print rstFiltered.RecordCountnIf rstFiltered.RecordCount <= 0 Thenn'''n '二级火箭点火ledgern 'Debug.Print "二级火箭准备:", kemuStrn '高阶的入口n If Stage < MaxStage Thenn kemuStr2 = kemuStrn n LeadStr(Stage + 1) = kemuStr2n 'Debug.Print "here LeadStr(Stage) :"; LeadStr(Stage)n n parentToChain Rcset_stage2, "一级科目='" & kemuStr2 & "'", kemuStr2, chainSheet, Stage + 1n Elsen n n n n '二级结束,熄火n End IfnElsennn nDo While Not rstFiltered.EOFnn 'Debug.Print "here2 LeadStr(Stage) :"; LeadStr(Stage), "stage:", Stagennn With Worksheets(chainSheet)nn n If rstFiltered.fields(2).Value <> "" Thenn n n n '''同名问题,自动认为是进入ledger'一种情况父与子相同的情况。解决同名的出口问题,否则死循环n If rstFiltered.fields(2).Value = kemuStr Thenn n ''''启动二级n If Stage = 1 Thenn 'Debug.Print "二级火箭准备:", kemuStrn kemuStr2 = kemuStrn LeadStr(Stage) = kemuStr2n parentToChain Rcset_stage2, "一级科目='" & kemuStr2 & "'", kemuStr2, chainSheet, 2n n Elsen n If Stage = 2 Then Debug.Print "会计科目不允许二级相同名称:", kemuStrn n If Stage = 0 Then Debug.Print "当前运行中有相同名称:", kemuStrn n End Ifn n n Elsen n offCols = offCols + 1n StageStr(Stage) = StageStr(Stage) + "," & rstFiltered.fields(2).Valuen n ''''输出一波火力,实现不同stage的对齐,竹节状数据,而且每层对齐。层级节节高,而每一节是个棵伞状Tree结构。n n str0 = rstFiltered.fields(4).Value & "," & rstFiltered.fields(5).Value & "," & rstFiltered.fields(6).Value & "," & rstFiltered.fields(3).Value & "," & exStrn .Cells(offRows, 1) = str0n .Cells(offRows, CoffsetColumns) = StageStr(1)n n If (Stage > 1) Thenn 'Debug.Print " LeadStr(Stage) :", LeadStr(Stage)n n .Cells(offRows, CoffsetColumns + Maxcols(Stage - 1) + 1) = LeadStr(Stage) & StageStr(Stage)n Elsen n End Ifn n n n offRows = offRows + 1n n '''''输出完了,继续再战n n parentToChain rstFiltered, "一级科目='" & rstFiltered.fields(2).Value & "'", rstFiltered.fields(2).Value, chainSheet, Stagen offCols = offCols - 1n StageStr(Stage) = mexn n End Ifn n Elsen n End Ifn End Withn'parentToChain rstFilteredn rstFiltered.movenextnLoopnEnd IfnEnd FunctionnnnSub fillMaxcols()noffCols = 3noffRows = 1nDim cnn As ObjectnDim Rcset As Object 'Rset竟然是保留字符号。nDim conncetStr, cnnStr, chainSheet, kemuStr, Rcset_1, Rcset_report, Rcset_2nSet cnn = CreateObject("ADODB.CONNECTION")nSet Rcset = CreateObject("ADODB.RECORDSET")nn'二级子节点,所有的父节点nSet Rcset_1 = CreateObject("ADODB.RECORDSET")nSet Rcset_2 = CreateObject("ADODB.RECORDSET")nSet Rcset_stage2 = CreateObject("ADODB.RECORDSET")nnSet Rcset_report = CreateObject("ADODB.RECORDSET")nnnnnnconncetStr = "Provider=Microsoft.ACE.OleDb.12.0;Extended Properties='Excel 12.0;HDR=YES';Data Source=" & ThisWorkbook.FullNamencnnStr = "Provider=Microsoft.ACE.OleDb.12.0;Extended Properties='Excel 12.0;HDR=YES'; Data Source=" & ThisWorkbook.FullNamencnn.Open cnnStrnts = "[期初余额_auto$A:M]"nnnnnSQL = "Select 序号,一级科目,二级科目,余额m,代码,方向,类别 from " & ts & " where 序号='ledger' and 一级科目<>''"nnRcset_stage2.Open SQL, cnn, 3, 1nnchainSheet = "链表图pro"nnSQL_1 = "select distinct 一级科目 from " & ts & " where 序号='ledger'"nRcset_1.Open SQL_1, cnn, 3, 1n'全域内不允许重名就简单,但报表科目与会计科目之间会有重名。nSQL_report = "Select 序号,一级科目,二级科目,余额m,代码,方向,类别 from " & ts & " where 序号='report' and 一级科目<>''"nRcset_report.Open SQL_report, cnn, 3, 1nnnoffCols = 1noffRows = 1nn'''''''''''''''''''nnMaxcols(1) = 1nkemuStr = "报表"nnparentToChain_only Rcset_report, "一级科目='" & kemuStr & "'", kemuStr, chainSheet, 1nn'Debug.Print Maxcols(1)nnnRcset_report.ClosennnoffCols = 1noffRows = 1nnMaxcols(2) = 1nn nn Do While Not Rcset_1.EOFn kemuStr = Rcset_1.fields(0).Valuen exStr = "ledger," & kemuStrn parentToChain_only Rcset_stage2, "一级科目='" & kemuStr & "'", kemuStr, chainSheet, 2n Rcset_1.movenextn Loopnn nMaxcols(2) = Maxcols(2) + Maxcols(1)nnnn'Debug.Print Maxcols(2)nnRcset_1.ClosennRcset_stage2.Closennncnn.ClosenEnd SubnnnnnnFunction parentToChain_only(Rcset, fstr, kemuStr, chainSheet, Optional Stage = 0)nnDim moffset, mex, rstFilterednnSet rstFiltered = CreateObject("ADODB.RECORDSET")nSet rstFiltered = Rcset.ClonennrstFiltered.Filter = fstrnnmoffset = offColsnnIf offCols > Maxcols(Stage) Then Maxcols(Stage) = offColsnn'Debug.Print stage, offCols, Maxcols(stage)nnmex = exStrn'''如果rstFiltered.countn'Debug.Print rstFiltered.RecordCountnnn nDo While Not rstFiltered.EOFn With Worksheets(chainSheet)n '.Cells(offRows, 1) = rstFiltered.fields(4).Value & "," & rstFiltered.fields(5).Value & "," & rstFiltered.fields(6).Value & "," & rstFiltered.fields(3).Value & "," & exStr + "," & rstFiltered.fields(2).Valuen offRows = offRows + 1n n n If rstFiltered.fields(2).Value <> "" Thenn '''同名问题,自动认为是进入ledger'一种情况父与子相同的情况。解决同名的出口问题,否则死循环n If rstFiltered.fields(2).Value = kemuStr Thenn n Debug.Print "当前运行有相同名称:", kemuStrn n n Elsen n offCols = offCols + 1n exStr = exStr + "," & rstFiltered.fields(2).Valuen parentToChain_only rstFiltered, "一级科目='" & rstFiltered.fields(2).Value & "'", rstFiltered.fields(2).Value, chainSheet, Stagen offCols = offCols - 1n exStr = mexn n End Ifn n Elsen n End Ifn End Withn'parentToChain rstFilteredn rstFiltered.movenextnLoopnnEnd Function
256.从实用的角度来说。报表只需要总账科目就可以。现在要解决的是会计科目的三级以上科目的问题。
257.百思不得其解。蓦然回首,顺序反了。老想着从子节点到根部,但发现数据污染,相互干扰。突然想到从根节点往叶子节点去,豁然开朗,别有洞天,漠漠水田飞白鹭,阴阴夏木啭黄鹂 。这人间胜景,可怜聊,两天来乌云压顶的脑扣扣。
蓦然回首,你咋还没走?青春有限,别自个添乱。

享受一波一路内置函数的快乐。一路dot点dot。 .Range("a1:a" & Rowsup).Find(fstr).Row
Sub 登报表数据pro(Optional ByVal mon = 1, Optional ByVal ts = "链表图pro", Optional ByVal Vts = "凭证_auto")nApplication.ScreenUpdating = FalsenDim cnn As Object, Rowsup, Rcset As Object, RcA1 As Object, Sumstr, TsstrnDim SQL$, SQA$, SQB$nSet cnn = CreateObject("ADODB.CONNECTION")nSet Rcset = CreateObject("adodb.recordset")ncnn.Open "Provider=Microsoft.ACE.OleDb.12.0;Extended Properties='Excel 12.0;HDR=NO'; Data Source=" & ThisWorkbook.FullNamenTsstr = " [" & ts & "$A:Z] "nSQL = "select * from [" & ts & "$A:Z]"nnSumstr = ""nFor i = 2 To 13nSumstr = Sumstr & "sum(F" & i & "),"nNextnnSumstr = Sumstr & "sum(F14)"nSQL = "select F16," & Sumstr & "from " & Tsstr & " group by F16"nn'Debug.Print SQLnnWith Worksheets(ts)n Rowsup = .Cells(1000, 1).End(xlUp).Rown Rcset.Open SQL, cnn, 3, 1n 'Debug.Print Rcset.RecordCountn n Do While Not Rcset.EOFn fstr = Rcset.fields(0)n frow = .Range("a1:a" & Rowsup).Find(fstr).Rown Debug.Print fstr, frown n n n n n Rcset.movenextn LoopnnnEnd WithnnnEnd Sub
OK。完成一个小目标。

出现一个小插曲,废了几个脑细胞后顺利通关。这个bug一捉,速度也上来了,思路也清晰了,腿脚也利索了,吃嘛嘛香,干嘛嘛棒。
'这里有bug,find默认是包含,而不是精确匹配
frow = .Range("a1:a" & Rowsup).Find(fstr, LookAt:=xlWhole).Row
Dim offCols, exStr, offRows, Rcset_stage2, Maxcols(256) As Integer, StageStr(256) As String, LeadStr(256) As StringnConst CoffsetColumns = 6nConst CoffsetRows = 1nDim MaxStagennnSub 报表过账pro_main()nn链表图reportnnts = "链表图pro"nnFor i = 1 To 5nn报表过账pro i, ts, "凭证_auto"nNextnWorksheets(ts).Selectn登报表数据pronnEnd SubnnnnSub 链表图report()n'全部采用程序计算而不用表公式实现所有功能。大量表公式影响效率n'excel表的输出速度慢得不是一点点。nnMaxcols(0) = 1nMaxStage = 1nnoffCols = 1noffRows = 1nnnDim cnn As ObjectnDim Rcset As Object 'Rset竟然是保留字符号。nDim conncetStr, cnnStr, chainSheet, kemuStr, Rcset_1, Rcset_reportnSet cnn = CreateObject("ADODB.CONNECTION")nSet Rcset = CreateObject("ADODB.RECORDSET")nn'二级子节点,所有的父节点nnnSet Rcset_report = CreateObject("ADODB.RECORDSET")nncnnStr = "Provider=Microsoft.ACE.OleDb.12.0;Extended Properties='Excel 12.0;HDR=YES'; Data Source=" & ThisWorkbook.FullNamencnn.Open cnnStrnts = "[期初余额_auto$A:M]"nchainSheet = "链表图pro"nnn'全域内不允许重名就简单,但报表科目与会计科目之间会有重名。nSQL_report = "Select 序号,一级科目,二级科目,余额m,代码,方向,类别 from " & ts & " where 序号='report' and 一级科目<>''"nRcset_report.Open SQL_report, cnn, 3, 1nnnWith Worksheets(chainSheet)n .Selectn .Cells.Clearn '.[a1].CopyFromRecordset Rcset_reportn 'Do While Not Rcset_2.EOFn '神奇的树,找到根节点,循环都省了。n n kemuStr = "报表"n exStr = kemuStrn parentToChain_1 Rcset_report, "一级科目='" & kemuStr & "'", kemuStr, chainSheetn 'Rcset_2.movenextn 'Loopn n ''''分裂变身n If 1 Thenn .Columns("A:A").Selectn Selection.TextToColumns Destination:=.Range("A1"), DataType:=xlDelimited, _n TextQualifier:=xlDoubleQuote, ConsecutiveDelimiter:=False, Tab:=True, _n Semicolon:=False, Comma:=True, Space:=False, Other:=False, TrailingMinusNumbers:=Truen End IfnEnd WithnnEnd SubnnFunction parentToChain_1(Rcset, fstr, kemuStr, chainSheet)nDim moffset, mexnDim rstFilterednSet rstFiltered = CreateObject("ADODB.RECORDSET")nSet rstFiltered = Rcset.ClonenrstFiltered.Filter = fstrnmoffset = offColsnmex = exStrnDo While Not rstFiltered.EOFnn With Worksheets(chainSheet)n ' .Cells.Clearn '.[A1].CopyFromRecordset rstFilteredn 'Debug.Print offRows, moffset, rstFiltered.RecordCount, mex, rstFiltered.fields(2).Valuen '+null值,整个字符串变nulln .Cells(offRows, 1) = rstFiltered.fields(2).Value & "," & rstFiltered.fields(3).Value & "," & String(12, ",") & exStr + "," & rstFiltered.fields(2).Valuen '.Cells(offRows, 1) = rstFiltered.fields(2).Value & "," & rstFiltered.fields(4).Value & "," & rstFiltered.fields(5).Value & "," & rstFiltered.fields(6).Value & "," & rstFiltered.fields(3).Value & "," & exStr + "," & rstFiltered.fields(2).Valuen offRows = offRows + 1n n If rstFiltered.RecordCount > 0 And rstFiltered.fields(2).Value <> "" Thenn offCols = offCols + 1n exStr = exStr + "," & rstFiltered.fields(2).Valuen parentToChain_1 rstFiltered, "一级科目='" & rstFiltered.fields(2).Value & "'", rstFiltered.fields(2).Value, chainSheetn offCols = offCols - 1n exStr = mexn End Ifn n End Withn'parentToChain rstFilterednn rstFiltered.movenextnLoopnnEnd FunctionnnnnnnnSub 报表过账pro(Optional ByVal mon = 1, Optional ByVal ts = "链表图pro", Optional ByVal Vts = "凭证_auto")nApplication.ScreenUpdating = FalsenDim cnn As Object, RowsupnDim SQL$, SQA$, SQB$nSet cnn = CreateObject("ADODB.CONNECTION")ncnn.Open "Provider=Microsoft.ACE.OleDb.12.0;Extended Properties='Excel 12.0;HDR=NO'; Data Source=" & ThisWorkbook.FullNamen'mon = 4n'''n'Rowsup = 列不为空所在行(1, 1000, ts) - 1 '减去标题行,数据区的行数nn科目余额表1 mon, VtsnnWith Worksheets(ts)nnRowsup = .Cells(1000, 1).End(xlUp).Rownn'本期发生数,本期发生m F12nSQLink = "select top " & Rowsup & " round([科目余额表1$a:m].F12,2) from [" & ts & "$A:A] left join [科目余额表1$a:m] on [" & ts & "$A:A].F1=[科目余额表1$a:m].F1"nncol = 2 + monn'没有标题栏n .Range(.Cells(1, col), .Cells(500, col)).ClearCommentsn ' Debug.Print SQLinkn .Cells(1, col).CopyFromRecordset cnn.Execute(SQLink)nEnd WithnnEnd SubnnnSub 登报表数据pro(Optional ByVal ts = "链表图pro", Optional ByVal Vts = "凭证_auto")n'''区分一下末级,还是计算科目会快点。n''''这样直接从科目余额表登账到报表。nApplication.ScreenUpdating = FalsenDim cnn As Object, Rowsup, Rcset As Object, RcA1 As Object, Sumstr, TsstrnDim SQL$, SQA$, SQB$nSet cnn = CreateObject("ADODB.CONNECTION")nSet Rcset = CreateObject("adodb.recordset")ncnn.Open "Provider=Microsoft.ACE.OleDb.12.0;Extended Properties='Excel 12.0;HDR=NO'; Data Source=" & ThisWorkbook.FullNamenTsstr = " [" & ts & "$A:Z] "nSQL = "select * from [" & ts & "$A:Z]"nnSumstr = ""nnnnFor i = 2 To 13nSumstr = Sumstr & "sum(F" & i & "),"nNextnnSumstr = Sumstr & "sum(F14)"nngcol = 16 '合计列名称nnnFor gcol = 16 To 22nn SQL = "select F" & gcol & "," & Sumstr & "from " & Tsstr & "where F" & gcol & " <> '' group by F" & gcoln Debug.Print SQLn n With Worksheets(ts)n Rowsup = .Cells(1000, 1).End(xlUp).Rown Rcset.Open SQL, cnn, 3, 1n 'Debug.Print Rcset.RecordCountn n Do While Not Rcset.EOFn ' fstr = Str(Rcset.fields(0))'str(NULL)会让excel意外退出,是个bugn fstr = Rcset.fields(0).Valuen '又是空值作怪,两面防空值n If fstr = "" Then GoTo ln n '这里有bug,find默认是包含,而不是精确匹配n frow = .Range("a1:a" & Rowsup).Find(fstr, LookAt:=xlWhole).Rown n n Debug.Print col, fstr, frown n For i = 2 To 14n .Cells(frow, i).Value = Round(Rcset.fields(i - 1).Value, 2)n n Nextn n Rcset.movenextn n nl:n Loopn n End Withn n Rcset.Closen nNextnnEnd Sub
256.一招解决结转凭证碍事问题。摘要前加“结转凭证-”。SQL中咔擦一刀。
出门碰到乌鸦了。是我想多了吗?
穷则独善其身,富则是我想多了。
后来发现世界上还是好人多。ADO这么有爱心的人怎么会为难别人呢,即使是你not like。
问题找到了,是bug。字段名不要加引号,就那么简单。
我们总说生活繁琐,其实是自己不懂得品味。其实,人生就那么简单,多点快乐,少点烦恼,累了就睡觉,醒了就微笑,闲了就找朋友多聚聚,做一个最单纯的人,走一段最幸福的路
SQL = " select * from [凭证_auto$A:J] where ‘摘要' not like '结转凭证-%'"
SQL = " select * from [凭证_auto$A:J] where 摘要 not like '结转凭证-%'"
257.到这里应是可以小节一下。对树的操作算是有点入门。从二维表走向空间树。走了许多弯路,关键在于对于树的层层汇总竟然是从上而下,而不是从下而上。这应该就是上蹿下跳、吵吵巴火要找的密室钥匙。原来如此,听罢肝肠断,一曲泪痕干。
晓镜但愁云鬓改,夜吟应觉月光寒。蓬山此去无多路,青鸟殷勤为探看
258.大牛。明天拜读。
ADO读取Excel出现字符串被截断而不完整的原因与解决办法 - 百度文库
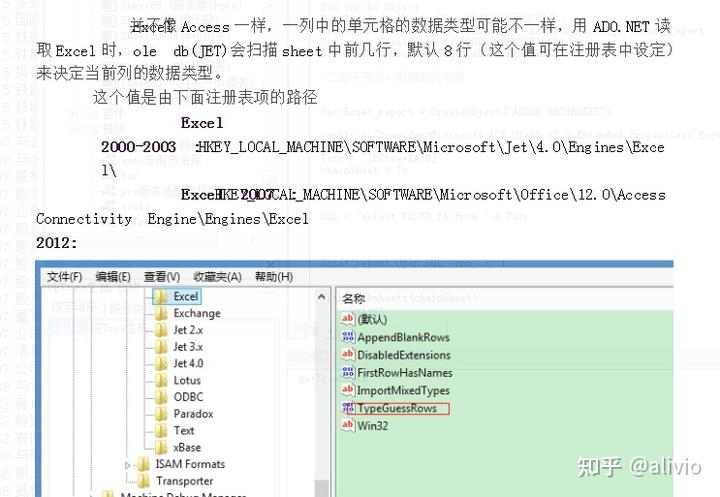
259.数据库对数据处理作用不可或缺。用python来实现树、链表总找不到汇总的办法,得自己造轮子。python里找到了排序的办法,也是通过自建类来实现,然后筛选出结果的话,肯定还要退一层,不能直接抓到内存的矩阵,因为压根人家不是用相邻内存块实现的。
260.找到一个,就知道这么成熟的数据结构,不可能不能从存储生成实例对象。
关系列表,这个称呼好,我给起的名字叫PC表。
就知道,了解了,马上安排。
这个功能是成图。需要的功能更复杂,要成单链,而且是要分级对齐成二维表。
这个功能对检查孤链的存在,很合适。
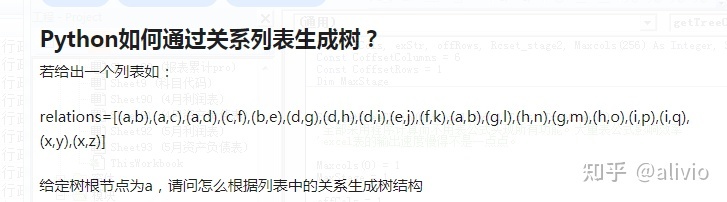
用这个库networkx ,('a', 'b') 表示顶点'a' 和顶点'b' 有一条边。
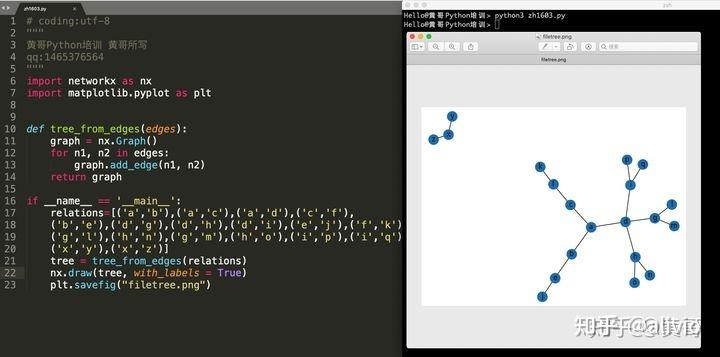
261.昨天卡在ADO拿不到混合数据中的字符串的门缝里。今天用EXCEL公式,把数字转成熟悉的样子。
搞出来了,但是出现了EXCEL表的闪退。
原来是PC表出现了问题。无限循环了。父子同名。


Dim offCols, exStr, offRows, Rcset_stage2, Maxcols(256) As Integer, StageStr(256) As String, LeadStr(256) As StringnConst CoffsetColumns = 6nConst CoffsetRows = 1nDim MaxStagennnSub getTreeChain(Optional ByVal Ts = "TreeChain")n'全部采用程序计算而不用表公式实现所有功能。大量表公式影响效率n'excel表的输出速度慢得不是一点点。nnMaxcols(0) = 1nMaxStage = 1nnoffCols = 1noffRows = 1nnnDim cnn As ObjectnDim Rcset As Object 'Rset竟然是保留字符号。nDim conncetStr, cnnStr, chainSheet, kemuStr, Rcset_1, Rcset_reportnSet cnn = CreateObject("ADODB.CONNECTION")nSet Rcset = CreateObject("ADODB.RECORDSET")nn'二级子节点,所有的父节点nnnSet Rcset_report = CreateObject("ADODB.RECORDSET")nncnnStr = "Provider=Microsoft.ACE.OleDb.12.0;Extended Properties='Excel 12.0;HDR=NO'; Data Source=" & ThisWorkbook.FullNamencnn.Open cnnStrnTstr = "[PCtree$D:E]"nchainSheet = TsnnnnSQL = "select * from " & TstrnnnnRcset_report.Open SQL, cnn, 3, 1nnnWith Worksheets(chainSheet)n .Selectn .Cells.Clearn .[a1].CopyFromRecordset Rcset_reportn 'Do While Not Rcset_2.EOFn '神奇的树,找到根节点,循环都省了。n n kemuStr = "刑事案由"n exStr = kemuStrn parentToChain_TreeChain Rcset_report, "F2='" & kemuStr & "'", kemuStr, chainSheetnnn n ''''分裂变身n If 0 Thenn .Columns("A:A").Selectn Selection.TextToColumns Destination:=.Range("A1"), DataType:=xlDelimited, _n TextQualifier:=xlDoubleQuote, ConsecutiveDelimiter:=False, Tab:=True, _n Semicolon:=False, Comma:=True, Space:=False, Other:=False, TrailingMinusNumbers:=Truen End IfnEnd WithnnEnd SubnnFunction parentToChain_TreeChain(Rcset, fstr, kemuStr, chainSheet)nDim moffset, mexnDim rstFilterednSet rstFiltered = CreateObject("ADODB.RECORDSET")nSet rstFiltered = Rcset.ClonenrstFiltered.Filter = fstrnmoffset = offColsnmex = exStrnDo While Not rstFiltered.EOFnn With Worksheets(chainSheet)n n '还有子节点 父节点输出一级n .Cells(offRows, 1) = exStr + "," & rstFiltered.fields(1).Valuenn offRows = offRows + 1n n '相当于一级科目不能于""n If rstFiltered.RecordCount > 0 And rstFiltered.fields(1).Value <> "" Thenn offCols = offCols + 1n exStr = exStr + "," & rstFiltered.fields(0).Valuen parentToChain_TreeChain rstFiltered, "F2='" & rstFiltered.fields(1).Value & "'", rstFiltered.fields(1).Value, chainSheetn offCols = offCols - 1n exStr = mexn End Ifn n End Withn'parentToChain rstFilterednn rstFiltered.movenextnLoopnnEnd Function
261.发现现在做的是一个简单的事情,因为程序明确知道根节点。如果,不知道,那又是另一回事情了。细思极恐。刚出狼窝,又入虎穴。城市套路深,还是回农村,古人诚不欺我。
不需要用到递归,可以直接不断循环找出 parentID直到parentID为空
回复 点赞
这位老兄给出了一个思路。就是盯住父节点。
突然发现,如果考虑到树的存储结构,找爹是件再容易不过的事情。
如果是PC结构的,找没爹的爹就是了。select * where 爹=''。一句搞定。
262.神办法解决报表项目与会计科目重名的问题。不需多想,不需多看,直接连上就开干。会计科目用二级搞定所有。为什么,因为报表项目与会计科目重名,还不是一路的可能性几乎为零。总没有那么欠的人,故意搞事情。再打个比方,有人和皇帝重名,还要和皇帝对着干,这样的系统肯定不是一个稳定的系统。就像三体世界,到头总有一个会被搞废掉。

263.碰到灵异事件了。这就是数据类型不确定的坑。.
竟然筛选不到!导入access也不行。
SQL = "select * from " & Tstr & " where 序号='report' and 一级科目<>'' and 二级科目=''"
Rcroot.Open SQL, cnn, 3, 1
把数字改成0就行了。太欺侮人了。
select * from [期初余额_auto$A:M] where 序号='report' and 一级科目<>'' and 二级科目='0'
加入一个“‘ ”单引号,或者一个返回“”的公式也可以。
用公式也行。
SQL = "select 一级科目 from " & Tstr & " where 序号='report' and 一级科目<>'' and iif(ISNULL(二级科目),'',二级科目)=''"
太恐怖了。太恐怖了。问题是它一会儿行,一会不行。<>是行的,=不行。
太委屈。太委屈,委屈巴巴,超想要大白一样的抱抱,来治愈我的一切。
什么岁月静好, 哪有什么岁月静好,不过是有人替你负重前行!
好人做到底,最讨厌做了一处,其他处处漏风。
奇怪的是access中都不行。可能这真是一个空值,其他的都是空字符串。
搞大了,搞大了,乖乖得搞死数据类型和默认值。要这样死相,太难看了。
什么岁月静好,你特么就是懒。而且是被别人拐了,还不知道转弯,以为自己走错了。继续轴,就给人家去填坑吧。傻叉。

264.还是ID的问题,如果要简单的汇总,那么需要全域范围内名称不能重复。如果只是两级,别说两级,就是N级,也解决不了重复混淆的问题。如果用ID就回到分区域代码的老路上去了,而且会发现老办法是最合理的。如果随机的代码组成链接,可以满足自由得要求,但是后期维护的时候将是一场噩梦。有点像UNICODE字符代码的分区管理。一块装不下只能在另外的区域找扩展区域,最终区域没有外部的登记表,就乱得爹妈不认。
无奈后面可能就还要回到老路上完成代码、代码位数的问题才能测地解决多级科目的问题。代码可以在代码可以在同一级内部实现自由。无论如何,同一一个父项目下面的子项不能出现重复。
表与表之间关联要解决的还是普遍的KEY问题。要有关联肯定要有不能混乱的KEY。可以有多个KEY,但不能混乱。
关系树的维护可以通过关系列表,也可以方程公式。关系列表只实现了科目的集合,不包含科目之间的关系,用聚合函数可以简单实现sum。
为什么要分表?为实现不用数字ID作为KEY。
如何展开三级科目?因为不同的二级科目下会有相同的三级科目名称。
这碰到了解决XPATH的问题。设计XPATH就是结构文档的问题,XML文档。
似乎XML文档作为视觉展示比较合适,如果作为数据存储,降低效率不说,数据的汇总计算还要倒回到关系数据库的方式上来。
凭证布局上可以采用,只显示两列,一级科目和二级科目,三级科目不显示。在原来的数据表格后面添加可自由生长的存储三级以上的科目数据。这样调和可是部分与数据存储的矛盾。
后面添加两列,表示该科目的xpath,相当于链表,相当于文字版的ID
晕了。发现削掉ID是一个错误的事情。或者说是个无法在关系数据中混的事情。或者转战XML文档。关键是XML中也还是要用到ID的。否则JQuery,$("#ID")这样的语句干什么吃的。只是ID随意,只要不在全域内重复就可以。只似乎找到了一个有意思的路径。走XML的路径。
上升到哲学高度。
人认知的意义范围是有限的,而机器的存储单元在无限延伸。人只有把有限的意义投身到无限的机器认知当中去。这是一项无限的为人民服务的伟大事业。
在有限的财务报表范围内可以不用ID的链表。在会计科目中使用ID,同时也把会计科目让给机器去登记与完成。
没办法的,用人类的语言与标记浩瀚的宇宙繁星,这事儿超出了言语能表达的范围。
另一面说,人自己使劲作吧,大脑产生出来的可识别概念远远不够用。你去给4G内存单元每个格子起个特别的网名试试看,看看脑袋够不够用。
个体的意识就是在概念的海洋中遨游,同时产生一些新的概念。
每次到哲学了,就是真正困难来的时候。
265.会计科目。厚道人家。
最新会计科目表(2021)_中国会计网
266.结构还是采取编码、名称的形式。发现会计科目的科目代码自带分级,反而比代码+父级代码+名称的形式更简单。
汇总的方式还是和分级的形式相同。代码自由度可以放在末级上面。只要不是有子科目的科目都可以给自动编码。删除代码的那个代码也要固定下来。
确定好代码长度后,就可以完成逐级汇总。字符串长度限制在256个字符,四个段位可以容纳10000个科目。百万级字典的词条,字符串需要6Byte,用Int类型4Byte。从存储上Int转字符串比较好。四个Byte,十进制字符串最多10000,如果是数值的话,可以表示2^32,4G,4*1024^3=42,9496,7296≈43亿字节,约标识43亿个词条,对于人类认知领域已经足够。
科目宽度为4个位,那么数字上,万位以上的数字表示科目级数,万位一下的数字表示科目本身。用一个八位数字可是表示10000级科目、每级10000个科目。所以用一个整型INT表示科目就可以了。可视化输出时转换成string。0~19999为一级科目,20000~29999为二级科目,N0000~N9999为N级科目,N为0~9999之间的数字。
用两个字节表示科目也够用。4个比特为表示级数,16级,够用了。每一级,4096个科目也足够用了。科目代码使用无符号短整型。
这样一个INT,四个字节可以表示自身代码+父级代码
计算的时候先用正负数表示,类别代码不编入。低两个字节解决唯一性,高两个字节解决链表。
清醒认识Python的真面目:
Python 支持三种不同的数值类型:整型(int)、浮点型(float)、复数(complex)。在其他的编程语言中,比如Java、C这一类的语言中还分有长整型(long)、短整型(short)这些类型。而python只有int类型,没有long型和short型。
int的范围
python2:
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1;
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1;
python3:
理论上长度是无限的(只要内存足够大)
EXCEL VBA委屈一点。最多三级科目。4+2+3,9位可用。简单10进制编码。

VBA的Int、long都是有符号的。int相当于C的short。

266.所有正襟危坐的,看不出一点破绽的都是通向巨坑的道路,伟大的作品有血有肉。
怎么在原基础上添加科目代码。
会计科目显示中文,不显示数字就可以了。代码单独开一列。三级科目的中文显示需要特别处理。或者再开一列,在打印凭证的时候,汇总到二级科目的单元格中。
方案采取二级以后的科目在二级中汇总显示。汇总采用科目代码,代码中文显示使用code表中的内容。这个对于存储来说也是合理的,减少重复的中文代码,在千万条记录的情况下,这个额外开销是不可承受的。
267.又找到一个好玩的东西:AutoCAD VBA
268.财务软件企业版,或者叫大数据版。
代码,最后做视觉呈现。
code2表含科目代码、三级中文显示,这两个都可以作为主KEY,是唯一的。
凭证的显示也使用中文显示格式,部分一级科目、二级科目。
在维护科目代码环节会多事情。
269.纪念一下,当初为了产生空白列是怎么干的。
SQL = "select 摘要,一级科目,二级科目,空白,借,空白,贷 from [" & ts & "$a:i] where 月份='" & mon & "月' and 凭证号=" & vIndex
270.就因为不知什么时候少了"step2",结果怎个程序中途停掉。安全、稳定、健壮提到日程上。
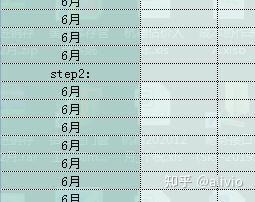
字符串后面,多了一个“,”,会在sps_低值易耗品中增加一个空值“”,这个太危险了。
ps_低值易耗品 = "杭州南方机电市场埃港五金机电经营部,杭州富阳国华门窗配件有限公司,杭州瑞博机电设备有限公司,杭州卢达贸易有限公司,"
sps_低值易耗品 = Split(ps_低值易耗品, ",")
公式中数组公式极易出错,点一下可能就破坏掉了。

流入、流出这些科目没有纳入报表的统计,出现报表不平。
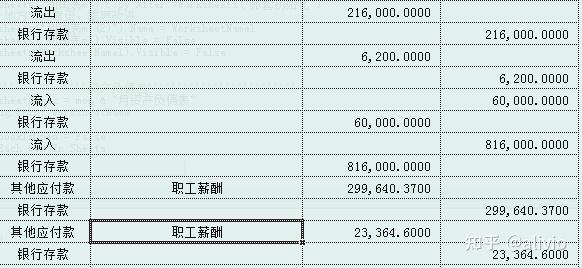
271.解决一行中借贷都有数据的问题。开心。
方法是,分别对借、贷做group,而不是一次完成group。不知道有没有干净一点写法,总感觉group by 后面又臭又长。
SQLA = "( select 月份,'',摘要,一级科目,二级科目,借,sum(贷) as 贷 from [凭证_auto$A:G] where 月份='" & mon & "月' and 一级科目<>'' and (iif(ISNULL(借),0,借)<>0 or iif(ISNULL(贷),0,贷)<>0) group by 月份,摘要,一级科目,二级科目,借 ) A"nnSQL = "select 月份,'',摘要,一级科目,二级科目,sum(借),贷 from " & SQLA & " where 月份='" & mon & "月' and 一级科目<>'' and (iif(ISNULL(借),0,借)<>0 or iif(ISNULL(贷),0,贷)<>0) group by 月份,摘要,一级科目,二级科目,贷 "

272.VBA设置Word不要保存恢复文件。
Options.SaveInterval = 0
273.InStrRev,还要这神仙函数。
sstr = "f:courtword.bat " & Selection.Text & " " & Left(ActiveDocument.Name, InStrRev(ActiveDocument.Name, "_")) & "orignial.txt"
Shell sstr, vbNormalFocus
274.还要这样的神仙公司与神仙专利。人工智能已经开始如当初的半导体、电脑、网络一样如火如荼。
275.学艺不精,或者叫怎么和我想的不一样。
select groupby 即使不用聚合函数,返回的竟然是、竟然是、竟然是唯一值。惊讶之情那一言表,竟然与distict同效果。谁给你的权利这样做?谁给你的狗胆可以这样设计?
pandas也是一死德性。group by里面没有的字段,又不能select,一group就变成唯一。我只想根据一个字段汇总,另外的保持原样就那么难吗?
气不过,继续挖:
不在group中又要显示,就是要套一个函数上去,MIN、MAX之类。
- Select Min(AuditDT) Min_AuditDT,AppNum,MIN(Id) from TA Group by AppNum)
278.AutoIt
WinGetHandle
| Success: | a handle to the window. |
Run ( "program" [, "workingdir" [, show_flag [, opt_flag]]] )
Local $iPID = Run("notepad.exe", "", @SW_SHOWMAXIMIZED)
目标从PID找到程序的主窗口。
Local $sWow64 = "" If @AutoItX64 Then $sWow64 = "Wow6432Node" Local $sFile = RegRead("HKEY_LOCAL_MACHINESOFTWARE" & $sWow64 & "AutoIt v3AutoIt", "InstallDir") & "include_ReadMe_.txt" ; Execute the readme file (.txt) with the default editor used for text files in Windows. Local $iPID = ShellExecute($sFile)
通过WinWait
Run("notepad.exe")
Local $hWnd = WinWait("[CLASS:Notepad]", "", 10)
Local $hControl = ControlGetHandle($hWnd, "", "Edit1")
ControlSetText($hWnd, "", "Edit1", "This is some text")
ControlSetText ( "title", "text", controlID, "new text" [, flag = 0] )
很多种方法获取窗口:
WinWaitActive("[TITLE:My Window; CLASS:My Class; INSTANCE:2]", "")
这个方法最香Retrieves a list of windows.
WinList("[REGEXPTITLE:(?i)(.*SciTE.*|.*Internet Explorer.*)]")
依葫芦画瓢,验证有效。真香,控制欲满足
;Local $aList=WinList("[REGEXPTITLE:(?i)(.*SciTE.*|.*Internet Explorer.*)]")
getprofile.au3
Local $filepro=WinGetHandle("[REGEXPCLASS:(FileLocatorProMainFrame*)]")nif @error ThennRun("f:FileLocator ProFileLocatorPro.exe")n$filepro=WinWait("[REGEXPCLASS:(FileLocatorProMainFrame*)]")nEndIfnnWinActivate($filepro)n;ControlSetText($filepro, "", "Edit3", "This is some text")nControlSetText($filepro, "", "Edit3", $CmdLine[1])nControlSetText($filepro, "", "Edit2", $CmdLine[2])nControlSetText($filepro, "", "Edit4", $CmdLine[3])nControlClick($filepro, "", "Button6")
老玩法,获取命令行参数。有点爱上AutoIt。多年前被折磨得,这会儿得到一点爽。
$CmdLine[0] 获取的是命令行参数的总数,在上例中$CmdLine[0]=3
$CmdLine[1]~$CmdLine[63] 获取的是命令行参数第1到第63位,这个方式最多只能获取63个参数,不过正常情况下是足够用的
$CmdLineRaw 获取的是未拆分的所有参数,是一个长字符串,这种情况下不局限与63个参数
点击操作,像极了控制浏览器,终于会师了。厉害了,我的AutoIt。可以昭告天下,杂家又升级啦!
ControlClick($hWnd, "", "Edit1")
word.bat
cd /d e:courtnecho ==========%1==========>>flog.txtn"notepad++.au3" %1n"getprofile.au3" %1nn::start "" "E:FileLocator ProFileLocatorPro.exe" -d E:python -c %1 -f %2 -rn::start fpro.bat %1 %2 %3nfindstr %1 E:python汉语词库*.txt >ftmp.txtnntype ftmp.txtntype ftmp.txt >>flog.txtnpython mjieba.py -w:%1npausenexit
疏通疏通,爽。
“身无彩凤双飞翼,心有灵犀一点通”
盖聪明疏通者戒于无断,湛静安舒者戒于后时,广心浩大者戒于遗忘
VBA:
Sub gethighlight() 'n Options.SaveInterval = 0n With Selectionn Debug.Print Selection.Textn sstr = Selection.Text & " " & Left(ActiveDocument.Name, InStrRev(ActiveDocument.Name, "_")) & "orignial.txt" & " " & ActiveDocument.Path n Debug.Print sstrn ShellExecute 0, "runas", "f:courtword.bat ", sstr, vbNullString, SW_SHOWNORMALn 'Shell sstr, vbNormalNoFocus n End With nEnd Sub
279.AutoIt 卡壳了。目前无法对其他程序中的Tab页操作。
记得有一个神器可以查看主窗口下所有下级窗口。先放放,凑活能用先。
280.当谁都在说python的时候,你需要了解Go。
现代语言肯定有现代语言的优势。
初步感觉,python是脚本的升级,Go类似于C#,是C的升级。
go支持并发,总而言之,从工程的角度上来看,对于大多数后台应用场景,选择Golang是极为明智的选择。 这样可以很轻松的兼顾运行性能、开发效率及维护难度这三大让诸多程序猿欲仙欲死的奇点。
astaxie/build-web-application-with-golang
C数组的全世界欲仙欲死的痛,go的slice让你一直爽。
go语言中的slice - Kingram - 博客园
281.用go重写自动生成凭证部分。
282.安装
The Go Programming Language
这个域名没被墙掉,说明危害性还不大。
按转包一路确定:
只有光秃秃的,ide、编辑器撒都没有。
安装完成后默认会在环境变量 Path 后添加 Go 安装目录下的 bin 目录C:Gobin,并添加环境变量 GOROOT,值为 Go 安装根目录C:Go。
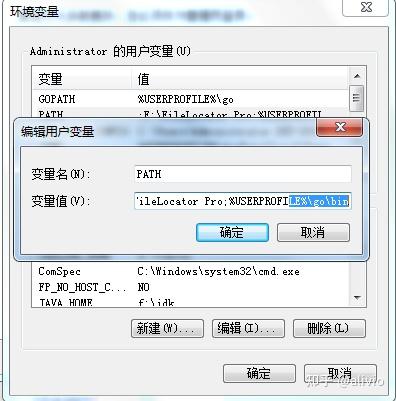
这样算是,有go了。
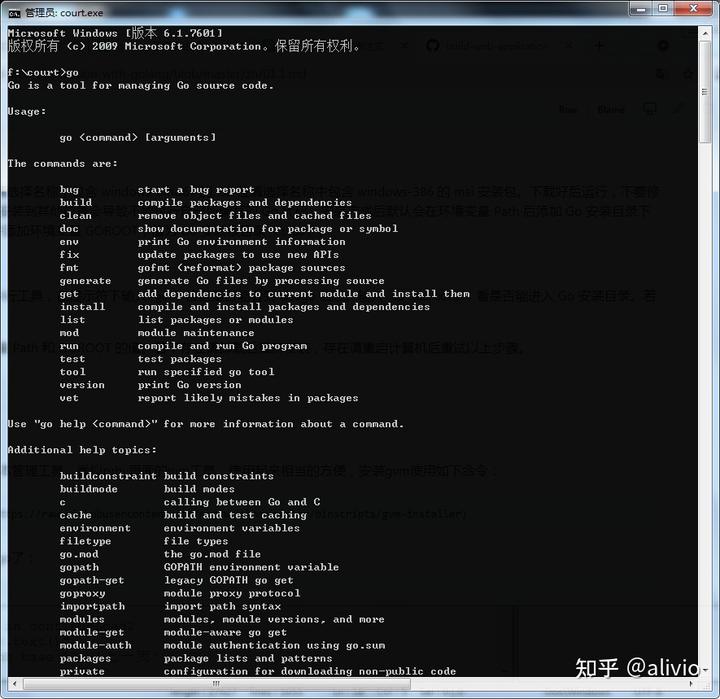
这是咋啦?
查明,由于安装时改变了默认的安装路径。手动修改吧
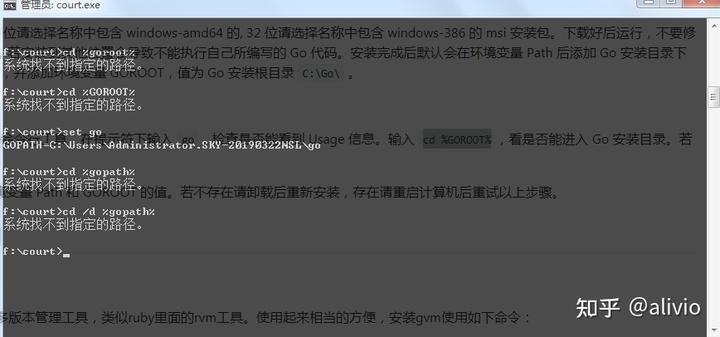
修改后:
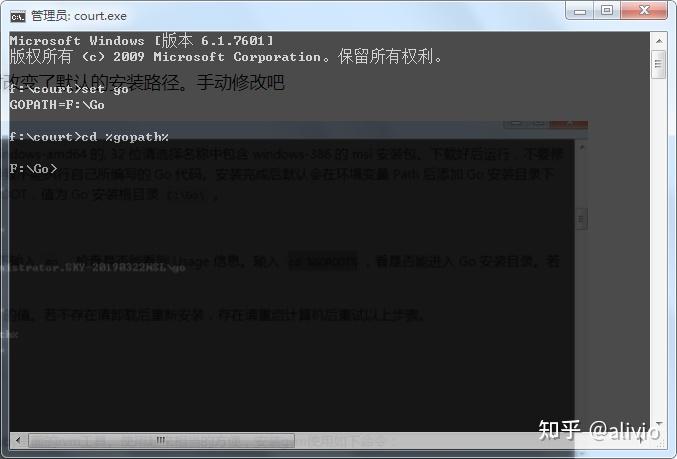
当看到需要版本控制,也就是说不通版本之间还不兼容。这绝对是个巨坑。
来个IDE当阿姨。找个阿姨好办事。没想到,竟然是VScode拔得头筹。
astaxie/build-web-application-with-golang
无法访问:
http://www.golang.org/
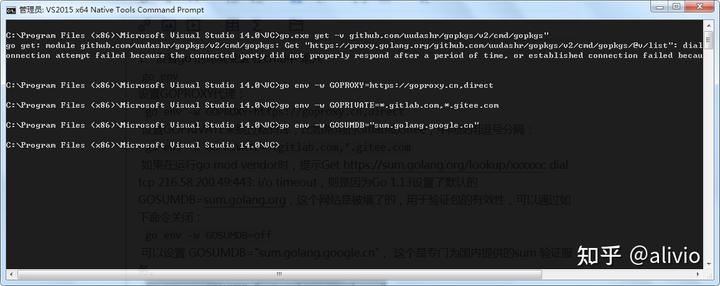
1、查看go 的环境变量 在cmd中 输入go env
设置GOPROXY代理:
go env -w GOPROXY=https://goproxy.cn,direct
设置GOPRIVATE来跳过私有库,比如常用的Gitlab或Gitee,中间使用逗号分隔:
go env -w GOPRIVATE=*.gitlab.com,*.gitee.com
如果在运行go mod vendor时,提示Get https://sum.golang.org/lookup/xxxxxx: dial tcp 216.58.200.49:443: i/o timeout,则是因为Go 1.13设置了默认的GOSUMDB=sum.golang.org,这个网站是被墙了的,用于验证包的有效性,可以通过如下命令关闭:
go env -w GOSUMDB=off
可以设置 GOSUMDB="http://sum.golang.google.cn", 这个是专门为国内提供的sum 验证服务。
go env -w GOSUMDB="sum.golang.google.cn"
"F:Gobingo.exe get -v http://github.com/uudashr/gopkgs/v2/cmd/gopkgs"
http://goproxy.cn
"F:Gobingo.exe get -v http://goproxy.cn/uudashr/gopkgs/v2/cmd/gopkgs"
天坑,填坑。差一点被这篇文章带跑偏了。其他问题没有解决,突然又冒出一个git命令来。
vscode 安装go第三方扩展包填坑记录
10、vscode自动安装失败,执行手动安装
第一步先在%GOPATH%srcgolang.orgx目录下打开git bash(如果没有对应的golang.org目录,可手功创建),执行git clone http://github.com/golang/tools。(手动安装第三方类包时,必须先安装tools类包)必须用git来clone,否则安装其他组件如go get -u -v github.com/cweill/gotests。会出现package golang.org/x/tools/imports:directory"D:GoPathsrcgolang.orgxtoolsimports" is not using a known version control system错误。
第二步tools下载好后,进入%GOPATH%srcgolang.orgxtoolscmdgorename目录,按shift+右键选择在此打开命令窗口,执行go install,guru也执行同样操作。
第三步在命令行窗口执行go get -u -v github.com/newhook/go-symbols,安装go-symbols。其他几个同样执行此操作,包链接见下。
有吃一鲸,powershell还要这功能。
Windows
打开你的 PowerShell 并执行
C:> $env:GO111MODULE = "on"nC:> $env:GOPROXY = "https://goproxy.cn"
添加两个环境变量后,手动下载,VScode失败的内容。
再加一个:
GOSUMDB="http://sum.golang.google.cn"
这基本已经不是一般人能够玩的了。
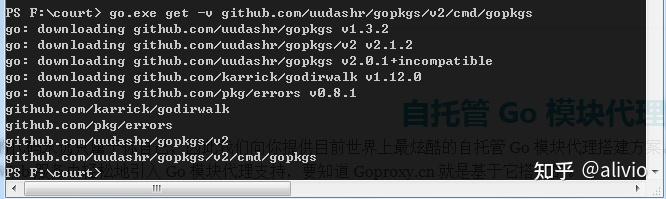
苦难的中国人,给开一个窗口就可以挤压生长。
go.exe get -v github.com/uudashr/gopkgs/v2/cmd/gopkgs
go.exe get -v http://github.com/ramya-rao-a/go-outline
go.exe get -v http://github.com/cweill/gotests/...
go.exe get -v http://github.com/fatih/gomodifytags
go.exe get -v http://github.com/josharian/impl
go.exe get -v http://github.com/haya14busa/goplay/cmd/goplay
go.exe get -v http://golang.org/x/lint/golint
go.exe get -v http://golang.org/x/tools/gopls
Installing 7 tools at F:Gobin in module mode.
go-outline
gotests
gomodifytags
impl
goplay
golint
gopls
如果在运行go mod vendor时,提示Get https://sum.golang.org/lookup/xxxxxx: dial tcp 216.58.200.49:443: i/o timeout,则是因为Go 1.13设置了默认的GOSUMDB=sum.golang.org,这个网站是被墙了的,用于验证包的有效性,可以通过如下命令关闭:ngoenv-w GOSUMDB=offn私有仓库自动忽略验证n可以设置 GOSUMDB="sum.golang.google.cn", 这个是专门为国内提供的sum 验证服务。ngoenv-w GOSUMDB="sum.golang.google.cn"goenv-w GOSUMDB="sum.golang.org"n-w 标记 要求一个或多个形式为 NAME=VALUE 的参数, 并且覆盖默认的设置
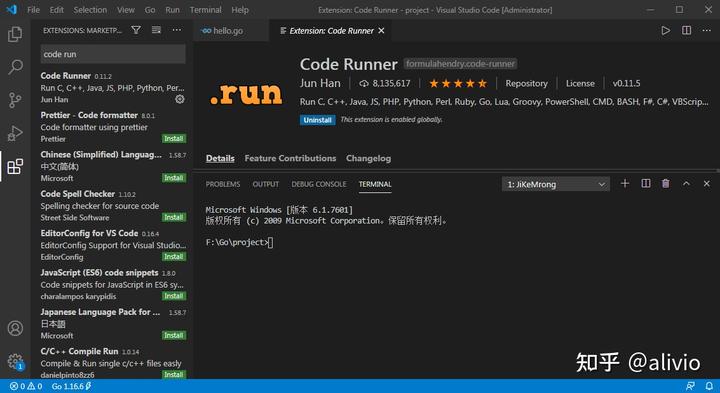
vscode,编译go,两条路,一条下载code runner。微软的东西就是华华丽丽,vim一样能有插件,如果不是做批处理,手摸的感觉还是vs。第二条,terminal。VBA都有这种窗口,想来VScode里肯定也不会缺席。
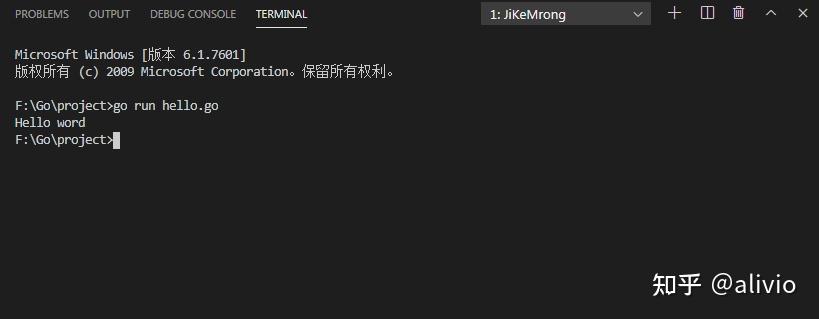
go run hello.go。没让人失望。两个小时的折腾,换来了一声“Hello word”。这百转千回,关键还在于环境变量的设置。一人一个说法,最终从http://goproxy.cn中找到了,windows破解问题的入口:设置环境变量。问题解决,就是有点费环境变量。
283.西天取经,九九八十一。边打妖怪,边前行。
数据的规范化,势在必行。
现在数据随便填,后期bug满天飞,这谁惹得祸?定是那斯data不合规。
先接通数据库与go:
go get -u http://github.com/go-sql-driver/mysql

顺路把git的问题解决了。天下一大怪,git不在git.com,在http://git-scm.com。
Git - Downloads
继续踩坑:
Golang 提供一个环境变量 GO111MODULE 来设置是否使用mod,它有3个可选值,分别是off, on, auto(默认值),具体含义如下:nnoff: GOPATH mode,查找vendor和GOPATH目录nnon:module-aware mode,使用 go module,忽略GOPATH目录nnauto:如果当前目录不在$GOPATH 并且 当前目录(或者父目录)下有go.mod文件,则使用 GO111MODULE, 否则仍旧使用 GOPATH mode。
$env:GO111MODULE = "on"
path和root的路径src均找不到所需的包,却在/pkg/mod下找到了。
人生的苦,有谁知道。为自己感动到了,为中国像自己一样学习者的人感动到了。
后查了下原因,发现是因为开了代理之后,
GO111MODULE=on
这个参数会将包放在那一块,所以这会儿可以关闭这个参数
go env -w GO111MODULE=off
然后重新下载依赖
go get -u http://github.com/go-sql-driver/mysql
package github.com/go-sql-driver/mysql: cannot download, F:Go is a GOROOT, not a GOPATH. For more details see: 'go help gopath'
手工复制:
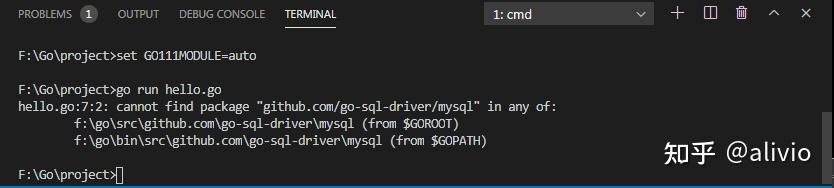
set GO111MODULE=auto
不行就,手工复制一下。目前还没找到修改配置的地方。
这一句非常有用:
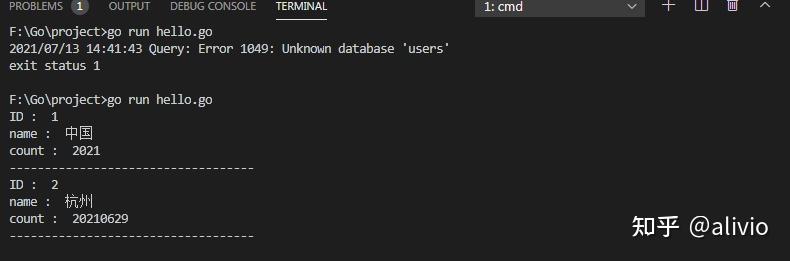
log.Fatal("Open: ", err)
终于见到了彩虹。这特娘的辛苦谁知道。怀疑人生,怀疑学习的成本。这该怎么继续。
虽然骂娘,但是错误处理、现代化的语法,可圈可点。python一时爽,错误一出有的忙。
panic,是什么东西?运行的时候,输出错误信息如下
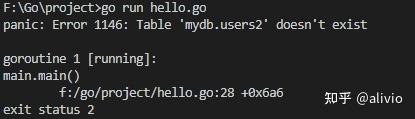
package mainnnimport (n "database/sql"n "fmt"n "log"n "time"nn _ "github.com/go-sql-driver/mysql"n)nn// ...nfunc main() {n db, err := sql.Open("mysql", "root:123456@/mydb")n if err != nil {n log.Fatal("Open: ", err)n //panic(err)n }n // See "Important settings" section.n db.SetConnMaxLifetime(time.Minute * 3)n db.SetMaxOpenConns(10)n db.SetMaxIdleConns(10)nn // Execute the queryn rows, err := db.Query("SELECT * FROM users")n if err != nil {n log.Fatal("Query: ", err)n //panic(err.Error()) // proper error handling instead of panic in your appn }nn // Get column namesn columns, err := rows.Columns()n if err != nil {n log.Fatal("Open: ", err)n //panic(err.Error()) // proper error handling instead of panic in your appn }nn // Make a slice for the valuesn values := make([]sql.RawBytes, len(columns))nn // rows.Scan wants '[]interface{}' as an argument, so we must copy then // references into such a slicen // See http://code.google.com/p/go-wiki/wiki/InterfaceSlice for detailsn scanArgs := make([]interface{}, len(values))n for i := range values {n scanArgs[i] = &values[i]n }nn // Fetch rowsn for rows.Next() {n // get RawBytes from datan err = rows.Scan(scanArgs...)n if err != nil {n log.Fatal("Open: ", err)n //panic(err.Error()) // proper error handling instead of panic in your appn }nn // Now do something with the data.n // Here we just print each column as a string.n var value stringn for i, col := range values {n // Here we can check if the value is nil (NULL value)n if col == nil {n value = "NULL"n } else {n value = string(col)n }n fmt.Println(columns[i], ": ", value)n }n fmt.Println("-----------------------------------")n }nn if err = rows.Err(); err != nil {n panic(err.Error()) // proper error handling instead of panic in your appn }nn}n
基于Dragonboat的几个具体例子,本文分享了几个常见的Go性能与使用问题。总结来说:
通过sharding分区减少contention是优化常用手段
做的再快也不可能比什么也不做更快,减少不必要操作比优化这个操作有效
多用Go内建的benchmark功能,数据为导向的做决策
官方提倡的东西肯定有他的道理,但在合适的情况下,需懂得如何无视某些官方的提倡
给,你要的 Go 学习路线图来啦
283.越来越专业。词汇,语法糖
举个例子:在 C 语言里用 a[i] 表示 *(a+i),用 a[i][j] 表示 *(*(a+i)+j),由此可见语法糖不是“现代语言”独有,这种写法简洁明了,易于理解。
a[i][j],一个连续的内存块,分成i块,每块有j个内存单元。每个内存单元只能存一个数据,或者一个连接指针。
再议,树、字典结构的实现:
所以,要在每一个节点上存一个名称,可以做地址序号与名称的映射表。也就是开两个二位数组,一个数组存名称,一个数组存数据。这两个数组对应数据的位置相同。通过名称(键)的位置就可以得到值得位置,一个通过值得位置反查得到名称的位置。
另一个办法就是结构体数组。一个二维数组存一个指向结构体的指针。
个人觉得前一个方法更好,可以实现双向的查找、索引、筛选、增加。后一个方法,逻辑上更容易理解,但是查找、使用的时候,还是要建立索引。索引其实就是前一个方法建立的两个数组或者其中的一个。
良月柒:不了解这12个语法糖,别说你会Java!
真是,一般培训机构绝对不会这么说。因为他们自己都说不清楚。就是不想把问题说简单。
似乎语法糖,就有点模板类的意思。这是当初看到尖括号就犯晕。
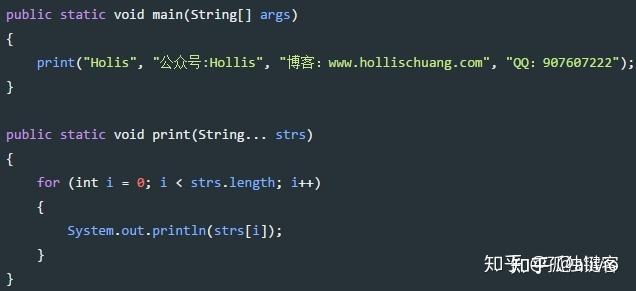
String...这个语法糖的本质是String strs[]。输入的是多个逗号分隔的字符,正好是字符串数组的定义方式。也可以理解为什main函数入口的String[] args,而且main的参数就等价于String args[]。被C++吓坏了,指针数组、数值指针的。指来指去,吓死人。
Java SE5提供了一种新的类型-Java的枚举类型,关键字enum可以将一组具名的值的有限集合创建为一种新的类型,而这些具名的值可以作为常规的程序组件使用,这是一种非常有用的功能。
enum就和class一样,只是一个关键字,他并不是一个类。
这种方法似乎可以解决在EXCEL中碰到的空值问题。加一层判断,在做会计运算的时候,只要默认为0,或者再摘要里默认“”,这其实是通过一个函数来判断实现。这样做的好处是,更加人性化,更加智能,但是成本就是编译后的程序逻辑更加复杂,同步带来的是系统开销的增加。大数据量的情况下,哪怕多查询一次都是小时级别的系统时间占用,更何况老是要验证空字符。如果每开一厘米就要验证是不是会发生交通事故,这车基本就成蜗牛了。问题是,何不最初就不产生空字符呢?或者就像C分配内存后直接就初始化0呢?
小赌怡情,大赌伤身。小搞搞就图个乐呵,偷偷懒无妨。大搞项目,每一列初始化时就能确定空值究竟是0,还是空字符串“”,或者统一都是字符。
一切的根源就出在,计算机存储的0不是我们眼睛看到的0。这样没什么奇怪的,都是数字1,1日元能等于1美元吗?地界不同,各有各的规矩。人鬼殊途,数字世界就是ghost的世界。
内部类又称为嵌套类,可以把内部类理解为外部类的一个普通成员。貌似,这个内部类无法访问外部类的变量。
以上代码编译后会生成两个class文件:OutterClass$InnerClass.class 、OutterClass.class 。
其实断言的底层实现就是if语言,如果断言结果为true,则什么都不做,程序继续执行,如果断言结果为false,则程序抛出AssertError来打断程序的执行。
代码很简单,for-each的实现原理其实就是使用了普通的for循环和迭代器。
284.蓦然回首,那人却在灯火阑珊处。前朝filelocator pro不能被全控,刹是不爽。今日再拉出来一看,全文显示可以与同一个mainframe里面。那天怎么抽风,会单独一个mainframe。这样就屁事没有。庸人自扰。dis。

285.还是回到EXCE上来。调试阶段EXCEL直观自由。解决Go读EXCEL
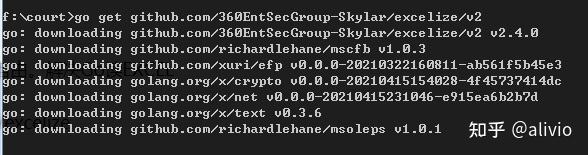
go get http://github.com/360EntSecGroup-Skylar/excelize
go get github.com/360EntSecGroup-Skylar/excelize/v2
下载了,但是找不到在哪里。
结果是因为文件名的原因。再正常情况下,下载后估计还要一个安装动作。但是现在手动情况下,下载pkg目录下,而包搜索在src目录下,而且下载的名称含有莫名其妙的字符。GOPATH再增加一个会怎么样?受不了这鸟气,只能铤而走险(结果可以,下次就可以直接在下载目录下修改,不用copy)。
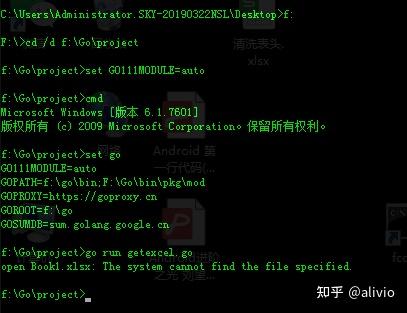
社会人就要建一个project.bat,多一步都受不了:
f:ncd /d f:Goprojectnset GO111MODULE=autoncmd
set GO111MODULE=auto
Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库
介绍 · Excelize 简体字文档go无法读取xlsb文件。真是虾掉了。
func (f *File) GetSheetName(index int) stringnvisible, err := f.GetColVisible("Sheet1", "D")nerr := f.GetRowVisible("Sheet1", 2)nnf, err := excelize.OpenFile("./Book1.xlsx")nif err != nil {n returnn}nfor index, name := range f.GetSheetMap() {n fmt.Println(index, name)n}
func (f *File) GetSheetList() []string
这个excel的处理库还是非常初级的。没有读取range的功能,没有直接把excel表转换成内部数组、字典、切片等的工具。
Golang 发展到现在是否有类似 Python 那样数据分析和爬虫包呢?
for-range时拷贝了被访问的列表(array、slice、hashmap等)。
当数组比较大时,for-range拷贝数组的开销也会比较大,在实际应用中应当避免这个开销。(这个值得商榷,有修改的时候copy正常,只是读取copy的毛啊。数组的增删操作底层都是通过copy来实现,这个没有毛病。不用copy难道用链表吗。)
为什么很少人用golang做大数据分析?
喵的,要是golang能有几个numpy、pandas级别的利器,谁还用python
世界非常现实:
因为苹果看中了这一块市场,想把python给挤出去,于是联合了谷歌和tensorflow的作者们,决定把swift推上科学计算和DL的首席语言的宝座……谷歌和苹果达成了这种同盟关系,因为要忠于该同盟,所以抑制了golang的发展,似乎不允许golang染指科学计算领域,所以谷歌里搞golang的那帮人只满足于在web上的成功,而不考虑科学计算领域……
没有人会告诉你的真相:
golang有它擅长的地方,也具备某些潜质。但目前而言,如果用于分析计算,哪怕是中等规模的运算,方便程度恐怕比excel还要差一些。
浮点数的工业精度和运算精度问题,日期的特殊格式问题,空值处理问题等等等等,这些都是困扰好多新手甚至高手的问题。
珍爱生命,科学计算请暂时远离golang,当然一般程序运算还是没问题的。
Go用来做数据科学---goplus_shelgi的博客-CSDN博客_goplus
再叙,多维数组。
没有必要死磕C有没有多维数组,多开几个一位数组不就解决了吗。要长得好看,就用语法糖给数组整整容。大道至简,不为世俗幻象所惑。
286.vscode有bug,vscode go的查包路径在GOPATH上不正确。导致命令行运行没问题,而代码源文件一直报错。太欺负人了。
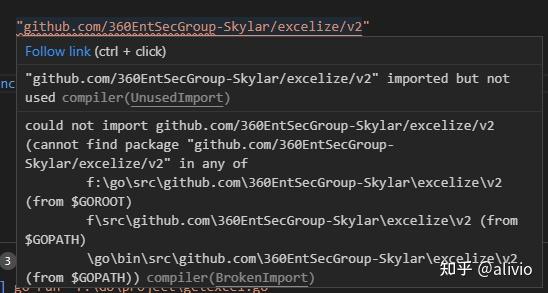
F:Goproject>go envnset GO111MODULE=onnset GOARCH=amd64nset GOBIN=nset GOCACHE=C:UsersAdministrator.SKY-20190322NSLAppDataLocalgo-buildnset GOENV=C:UsersAdministrator.SKY-20190322NSLAppDataRoaminggoenvnset GOEXE=.exenset GOFLAGS=nset GOHOSTARCH=amd64nset GOHOSTOS=windowsnset GOINSECURE=nset GOMODCACHE=f:gobinpkgmodnset GONOPROXY=*.gitlab.com,*.gitee.comnset GONOSUMDB=*.gitlab.com,*.gitee.comnset GOOS=windowsnset GOPATH=f:gobinnset GOPRIVATE=*.gitlab.com,*.gitee.comnset GOPROXY=https://goproxy.cnnset GOROOT=f:gonset GOSUMDB=sum.golang.google.cnnset GOTMPDIR=nset GOTOOLDIR=f:gopkgtoolwindows_amd64nset GOVCS=nset GOVERSION=go1.16.6nset GCCGO=gccgonset AR=arnset CC=gccnset CXX=g++nset CGO_ENABLED=1nset GOMOD=NULnset CGO_CFLAGS=-g -O2nset CGO_CPPFLAGS=nset CGO_CXXFLAGS=-g -O2nset CGO_FFLAGS=-g -O2nset CGO_LDFLAGS=-g -O2nset PKG_CONFIG=pkg-confignset GOGCCFLAGS=-m64 -mthreads -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=C:UsersADMINI~1.SKYAppDataLocalTempgo-build1281800375=/tmp/go-build -gno-record-gcc-switches
287.了解了Go的老底以后,决定还是先用python写一遍,看看效果。效果不行再用Go或者直接上C。python的[for in if ]骚操作太迷人。
288.合同、开票、收款管理
这个猛将,四个引号才能代表一个引号
="""" & A2 & """"
excel如何将字符串转换成公式?
这竟然成了一个问题。indirect不行,evalute没这函数。
单元格-选择性粘贴-数值。可以实现,但是让一个不懂的这么去操作,肯定是找麻烦的。她会这么去操作就不需要你去这么教她了。
EVALUATE函数是office2013上的函数,office2007要么自己搞。
在wps中解决了。有evaluate
excel的动态公式:
=EVALUATE("=VLOOKUP("&""""&"*合同金额*"&""""&","&A2&"!A:A,1,0)")
=EVALUATE("=MATCH("&""""&"合计"&""""&","&A2&"!A:A,0)")
是不是到了卸载office2007,改office2016得时候啦?想想那么多的ado连接用的还是ole12,想想还是算了。
问:2023年锅炉价格/多少钱?
上一篇:骄龙九变——从“瓦良格”号重型载机巡洋舰到“辽宁”号航空母舰(4)
下一篇:@2







