工业蒸汽量预测比赛全流程解析(附详细Python代码)
采用的数据集情况本文所采用的数据集来自于阿里云天池比赛,比赛的链接地址为:阿里云天池工业蒸汽量预测比赛链接其中所下载的数据集
采用的数据集情况
本文所采用的数据集来自于阿里云天池比赛,比赛的链接地址为:阿里云天池工业蒸汽量预测比赛链接
其中所下载的数据集包括两个txt文件:zhengqi_train.txt(训练集)和zhengqi_test.txt(测试集)
数据导入
因本文的主要目的是以介绍整个挖掘流程为主,因此采用根据需要逐步导入所需要的库的形式,以下先导入numpy和pandas两个库。
import numpy as npnimport pandas as pd
使用pandas导入已经预先下载并存放在本地的训练集和测试集,结合本次的数据集为txt文件,并且数据之间的分隔符为't',因此导入文件的代码如下:
df_train=pd.read_csv(r'D:zhengqizhengqi_train.txt',sep='t')ndf_test=pd.read_csv(r'D:zhengqizhengqi_test.txt',sep='t')
数据概览
使用head查看训练集和测试集前5条数据的情况
df_train.head()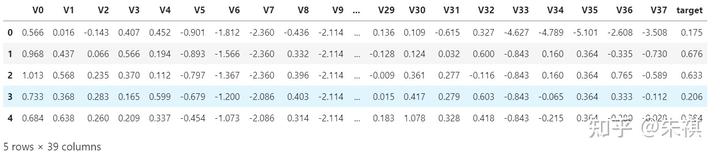
从图中可以看到,训练集总共有39列,其中包括V0至V37共38个特征,target为本次的预测标签值。
df_test.head()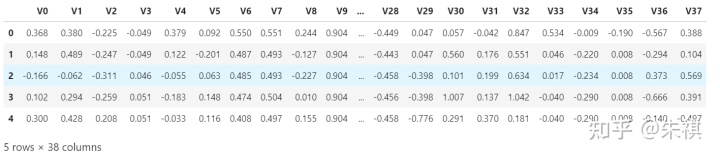
测试集总共有38列,其中包括V0至V37共38个特征,没有target,本次的预测就是需要根据训练完成的模型,提交测试集的target值。
使用info查看训练集和测试集的整体情况如下:
df_train.info()

可以看到,训练集的数据总数为2888条,因为Python默认的index排序是从0开始,所以index显示为0至2887条。non-null代表数据中没有缺失值,因此不需要对于数据进行缺失值填充;float64(39)代表39列数据全部为浮点形式数值数据,不需要进行格式上的转换。
df_test.info()
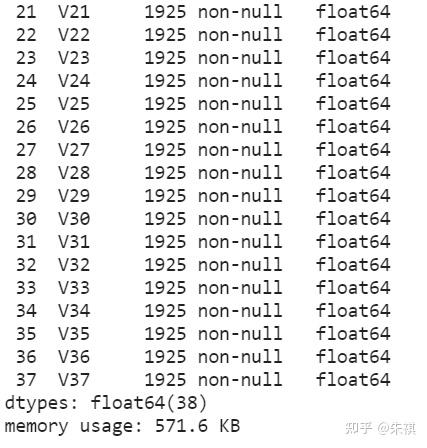
测试集的数据总数为1925条,index序号为0至1924条。测试集中的数据同样没有缺失值;float64(38)代表38列数据全部为浮点形式数值数据,不需要进行格式上的转换。因此,训练集数据的总体情况和测试集数据是一致的。
特征工程
加载接下去要使用的两个库,matplotlib和seaborn都是Python中常用的可视化工具库。
import matplotlib.pyplot as pltnimport seaborn as sns
用以下代码提取出训练集中所有的特征标签,方便之后使用:
#提取df_train中的特征标签,并将起转换成列表形式nfeature_list=list(df_train.columns)n#为方便之后使用,去掉列表中被一并提取出来的target标签,确保仅留特征标签nfeature_list.remove('target')n#显示特征标签列表nfeature_list
feature_list即特征标签列表如下:
['V0','V1','V2','V3','V4','V5','V6','V7','V8','V9','V10','V11','V12','V13','V14','V15','V16','V17', 'V18', 'V19', 'V20', 'V21', 'V22', 'V23', 'V24','V25', 'V26', 'V27', 'V28', 'V29', 'V30', 'V31',
'V32', 'V33', 'V34', 'V35', 'V36', 'V37']
数据分布情况核实
首先需要核实的是训练集的各特征数据分布情况是否和测试集一致,当两者出现较大差异时,将会导致模型失效的情况,可视化对比过程如以下代码所示:
#对于特征标签列表feature_list中的特征标签进行操作,逐个绘制单变量数据n分布图,训练集和测试集的相同特征分布情况绘制在同一张图上以方便比对nfor i in feature_list:n sns.distplot(df_train[{i}])n sns.distplot(df_test[{i}])n plt.title(i)n plt.show()
对于特征数较多的数据集,采用subplot方式绘制各类图是更好的选择,本文因为特征数并不算太多,为了更清晰的进行可视化展现,采用了一个for循环进行逐幅绘制的方式。
从V0到V37,总共生成了38幅单变量数据分布图,其中蓝色的是某特征训练集的数据分布情况,黄色的是测试集的数据分布情况。根据这38幅图,可以判断训练集和测试集各个特征的数据分布是否一致。以下选取典型的4幅作说明:
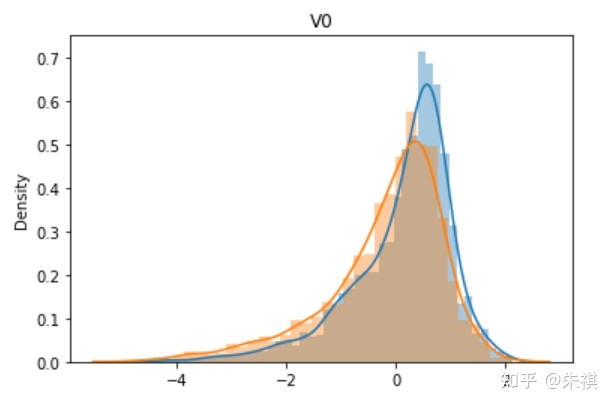
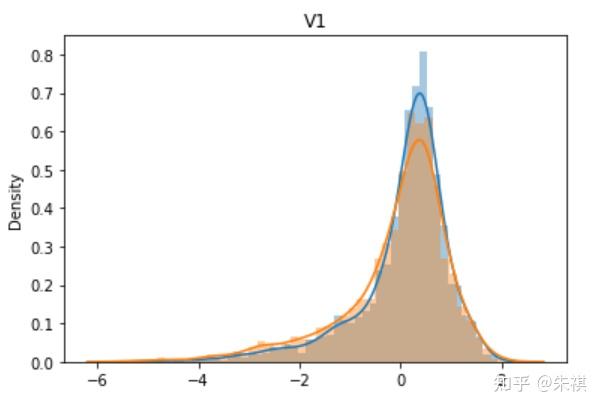
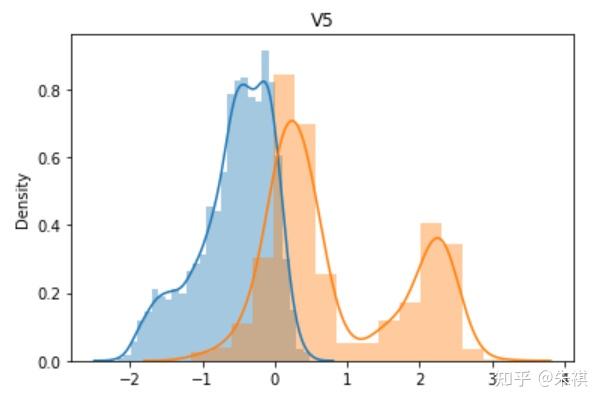
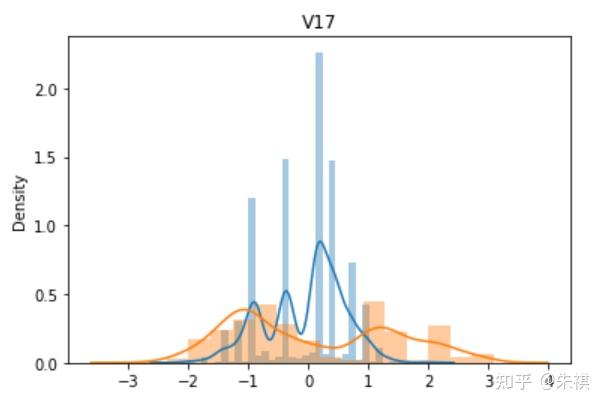
理想状态下,针对同一特征,训练集的数据分布曲线应该和测试集的数据分布曲线完全一致,但是这在实际过程中并不多见。如V0和V1两个特征的分布图可以发现,虽然训练集和测试集的数据分布情况略有差异,但仍然可以认为是分布情况一致的。而V5和V17特征图清晰的反映了数据分布不一致的情况。
同时在训练集和测试集中将数据分布不一致的特征去除,代码如下:
df_train=df_train[['V0','V1','V3','V4','V8','V10','V12','V15','V16','V18','V24','V25','V26','V28','V29','V30','V31','V32','V33','V34','V36','target']]ndf_test=df_test[['V0','V1','V3','V4','V8','V10','V12','V15','V16','V18','V24','V25','V26','V28','V29','V30','V31','V32','V33','V34','V36']]
因为训练集和测试集的特征经过了筛选都发生了变化,为了方便之后的操作,重新提取出训练集中所有的特征标签,更新特征标签列表feature_list:
#提取df_train中的特征标签,并将起转换成列表形式nfeature_list=list(df_train.columns)n#为方便之后使用,去掉列表中被一并提取出来的target标签,确保仅留特征标签nfeature_list.remove('target')n#显示特征标签列表nfeature_list
更新后的特征标签列表feature_list如下:
['V0','V1','V3','V4','V8','V10','V12','V15','V16','V18','V24','V25','V26','V28','V29','V30','V31','V32','V33','V34','V36']
相关性分析
对于训练集进行相关性分析,所采用的方法为计算皮尔逊相关系数,Python中可以直接在数据集上采用corr的方法,默认的相关系数计算方式就是皮尔逊相关系数。
df_train.corr()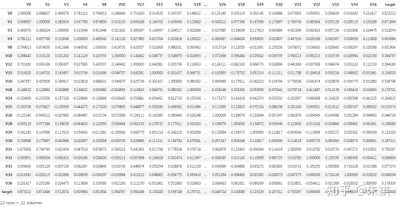
本文的案例我们只分析各特征标签与预测标签(target)之间的相关性,查看上表的最后一列相关系数计算结果,相关系数的绝对值大于0.5的为强相关性,小于0.5的为弱相关性,0附近的为没有相关性,系数为正代表正相关,系数为负代表负相关。
以可视化方法绘制特征标签与预测标签(target)的散点图,与相关系数的计算结果进行相互校对:
for i in feture_list:n sns.scatterplot(df_train[f'{i}'],df_train['target'])n plt.show()
在生成的所有散点图中挑选几幅典型的图来说明不同的相关系数下,散点图的大致形状:
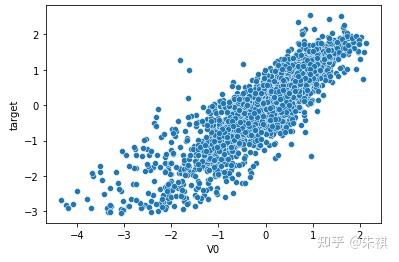
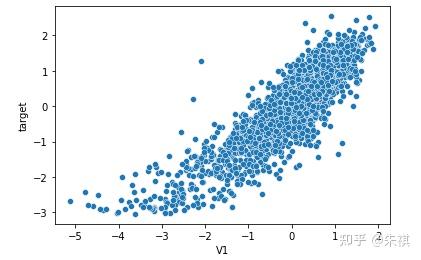
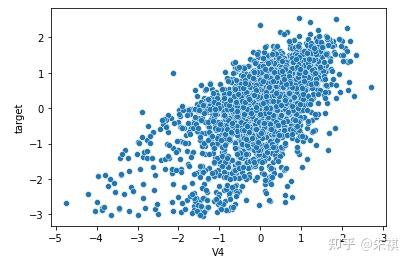
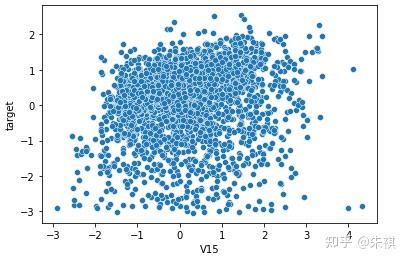
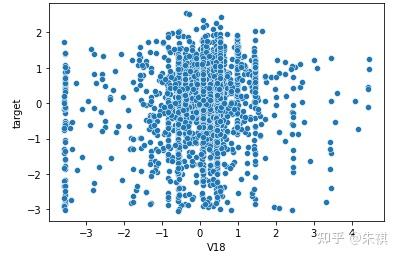
以0.5为界限,同时在训练集和测试集中去除相关系数绝对值低于0.5的特征,确保被输入模型进行训练的特征与预测目标值有较强的相关性。
df_train=df_train[['V0','V1','V3','V4','V8','V12','V16','V31','target']]ndf_test=df_test[['V0','V1','V3','V4','V8','V12','V16','V31']]
因训练集和测试集的特征再次经过筛选,因此再次更新特征标签列表feature_list:
#提取df_train中的特征标签,并将起转换成列表形式nfeature_list=list(df_train.columns)n#为方便之后使用,去掉列表中被一并提取出来的target标签,确保仅留特征标签nfeature_list.remove('target')n#显示特征标签列表nfeature_list
更新后的特征标签列表feature_list如下:
['V0','V1','V3','V4','V8','V12','V16','V31']
正态分布检验
对于完成进一步筛选的数据集做正态分布检验,以确定是否需要进一步将数据尽可能转换成正态分布的形式,本文同样同时采用指标计算的方法和可视化的方法来同时进行正态分布检验。
导入正态分布检验所需要用到的库:
from scipy import stats
首先检验各个特征中数据的偏度,偏度定义中包括正态分布(偏度=0),右偏分布(也叫正偏分布,其偏度>0),左偏分布(也叫负偏分布,其偏度<0)。
for i in feture_list:n skew = stats.skew(df_train[f'{i}'])n print(f'the skew value of feture {i} is {skew}')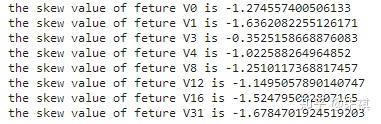
根据偏度的检验结果,各个特征的数据都为左偏,但是总体都满足正态分布。之后检验各个特征中数据的峰度。若峰度≈0,分布的峰态服从正态分布;若峰度>0,分布的峰态陡峭(高尖);若峰度<0,分布的峰态平缓(矮胖)。
for i in feture_list:n kurtosis = stats.kurtosis(df_train[f'{i}'])n print(f'the kurtosis value of feture {i} is {kurtosis}')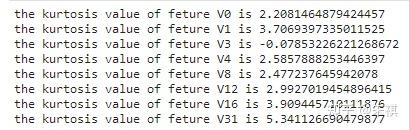
根据偏度的检验结果,各特征的数据总体都满足正态分布。采用可视化的方法对于指标的计算结果进行确认,结果如下:
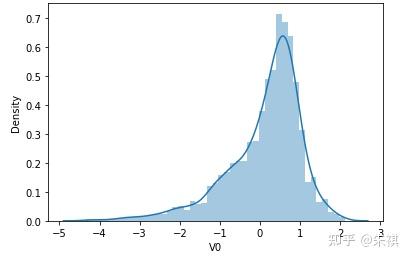
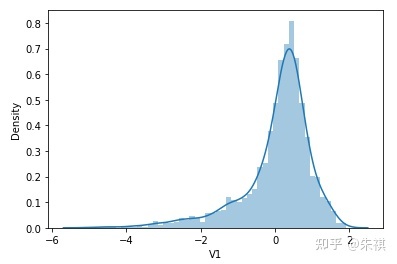
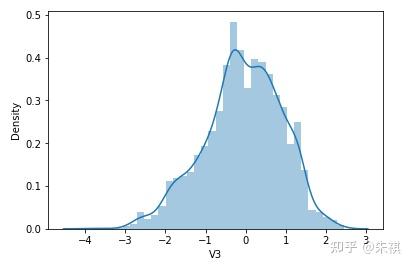
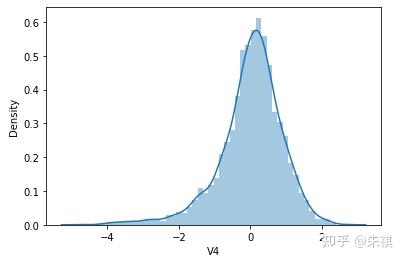
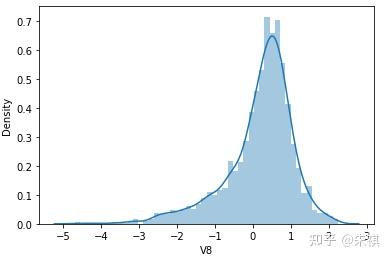
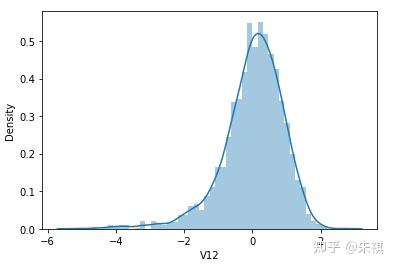
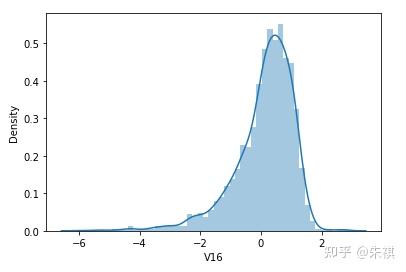
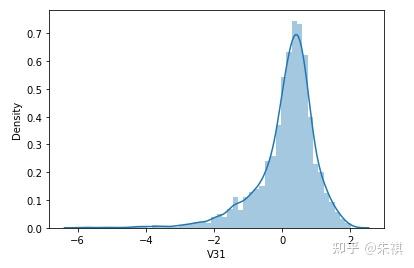
可视化的检验结果与指标检验结果一致,因此正态分布检验的结论为:各特征数据基本符合正态分布,本文后续不对数据进行正态分布转换处理。
数据集拆分
因为本文的数据来自比赛,因此测试集单独提供,测试集的预测结果作为比赛的评定指标。对于训练集进一步拆分出交叉验证集以判断模型的预测效果,同时确保交叉验证集的数据与训练集数据完全独立:
from sklearn.model_selection import train_test_splitndf_train_value, df_vali_value, df_train_target, df_vali_target=train_test_split(df_train_value, df_train_target, test_size=0.25,random_state=1)
拆分完的数据集如下所示:
df_train_value:训练集特征数据集(总数据的75%)
df_train_target:训练集的预测目标数据(总数据的75%)
df_vali_value:交叉验证集特征数据集(总数据的25%)
df_vali_target:交叉验证集的预测目标数据(总数据的25%)
模型训练及检验
对于df_train_value,df_train_target,df_vali_value,df_vali_target的index进行重置,确保所有数据都从第0条开始排序:
df_train_value=df_train_value.reset_index(drop=True)ndf_vali_value=df_vali_value.reset_index(drop=True)ndf_train_target=df_train_target.reset_index(drop=True)ndf_vali_target=df_vali_target.reset_index(drop=True)
对重置完成的各个数据集,将数据转换成矩阵形式供后续使用:
df_train_value=np.array(df_train_value)ndf_vali_value=np.array(df_vali_value)ndf_train_target=np.array(df_train_target)ndf_vali_target=np.array(df_vali_target)
加载验证指标MSE:
from sklearn.metrics import mean_squared_error
算法1:XGBoost
建立模型并进行训练:
import xgboost as xgbnmodel_xgb=xgb.XGBRegressor(max_depth=5, learning_rate=0.1, n_estimators=160, silent=True, objective='reg:linear')nmodel_xgb.fit(df_train_value,df_train_target)
对于交叉验证集特征数据集df_vali_value进行预测:
predict_xgb=model_xgb.predict(df_vali_value)
将预测结果及交叉验证集的预测目标数据对比进行指标验证:
mean_squared_error(df_vali_target,predict_xgb)
在未进行深度调参的情况下,采用XGBoost进行预测得出的MSE为0.128。在此基础上抽取交叉验证集的100组数据采用可视化手段直观检验预测效果:
plt.plot(df_vali_target[0:101])nplt.plot(predict_xgb[0:101])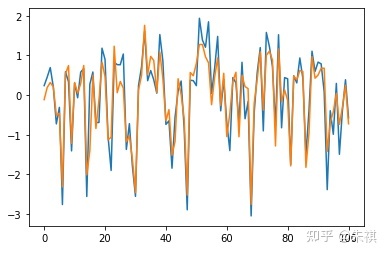
算法2:GBDT Regression
建立模型并进行训练
from sklearn.ensemble import GradientBoostingRegressornmodel_gbdt=GradientBoostingRegressor(n loss='ls'n, learning_rate=0.03n, n_estimators=500n, subsample=1n, min_samples_split=2n, min_samples_leaf=1n, max_depth=3n, init=Nonen, random_state=Nonen, max_features=Nonen, alpha=0.9n, verbose=0n, max_leaf_nodes=Nonen, warm_start=Falsen)nmodel_gbdt.fit(df_train_value,df_train_target)
对于交叉验证集特征数据集df_vali_value进行预测:
predict_gbdt=model_gbdt.predict(df_vali_value)
将预测结果及交叉验证集的预测目标数据对比进行指标验证:
mean_squared_error(df_vali_target,predict_gbdt)
在未进行深度调参的情况下,采用GBDT进行预测得出的MSE为0.13。在此基础上抽取交叉验证集的100组数据采用可视化手段直观检验预测效果:
plt.plot(df_vali_target[0:101])nplt.plot(predict_gbdt[0:101])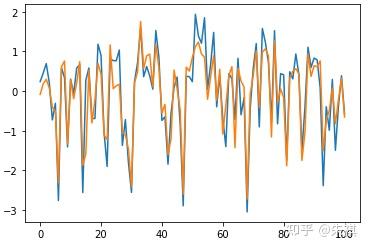
算法3:Random Forests
建立模型并进行训练:
from sklearn.ensemble import RandomForestRegressornmodel_RF=RandomForestRegressor(n_estimators=200, random_state=0)
对于交叉验证集特征数据集df_vali_value进行预测:
predict_RF=model_RF.predict(df_vali_value)
将预测结果及交叉验证集的预测目标数据对比进行指标验证:
mean_squared_error(df_vali_target,predict_RF)
在未进行深度调参的情况下,采用Random Forests进行预测得出的MSE为0.123。在此基础上抽取交叉验证集的100组数据采用可视化手段直观检验预测效果:
plt.plot(df_vali_target[0:101])nplt.plot(predict_RF[0:101])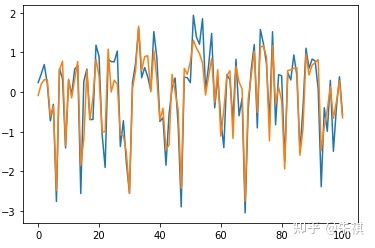
算法4:Bayesian Linear Regression
建立模型并进行训练:
from sklearn import linear_modelnmodel_BR=linear_model.BayesianRidge()nmodel_BR.fit(df_train_value,df_train_target)
对于交叉验证集特征数据集df_vali_value进行预测:
predict_BR=model_BR.predict(df_vali_value)
将预测结果及交叉验证集的预测目标数据对比进行指标验证:
mean_squared_error(df_vali_target,predict_BR)
采用Bayesian Linear Regression进行预测得出的MSE为0.125。在此基础上抽取交叉验证集的100组数据采用可视化手段直观检验预测效果:
plt.plot(df_vali_target[0:101])nplt.plot(predict_BR[0:101])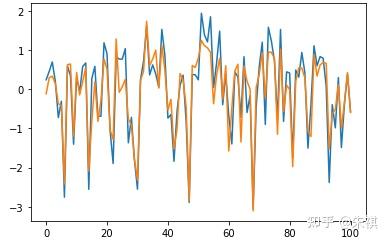
算法5:Linear Regression
建立模型并进行训练:
from sklearn.linear_model import LinearRegressionnmodel_LR=LinearRegression()nmodel_LR.fit(df_train_value,df_train_target)
对于交叉验证集特征数据集df_vali_value进行预测:
predict_LR=model_LR.predict(df_vali_value)
将预测结果及交叉验证集的预测目标数据对比进行指标验证:
mean_squared_error(df_vali_target,predict_LR)
采用Linear Regression进行预测得出的MSE为0.125。在此基础上抽取交叉验证集的100组数据采用可视化手段直观检验预测效果:
plt.plot(df_vali_target[0:101])nplt.plot(predict_LR[0:101])
测试集预测
检测测试集状态是否正常:
df_test.head()
df_test.info()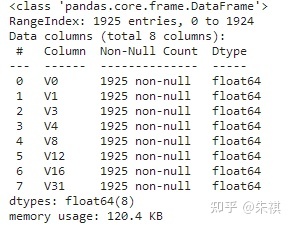
将测试集转换为矩阵形式:
df_test=np.array(df_test)
采用MSE指标最低的模型进行预测,这里采用Random Forests算法模型:
predict_test=model_RF.predict(df_test)
制作提交文件完成实验
按提交要求将预测结果predict_test作为新的一列插入测试集zhengqi_test.txt,标签为target:
test_submit=pd.read_csv(r'D:天池工业蒸汽量预测zhengqi_test.txt',sep='t')ntest_submit['target']=predict_test
通过头五组数据查看提交文件的状态:
test_submit.head()