jvm 即时编译器
在jdk7以后出现clinet编译器和server编译器,默认为client模式运行,jdk8以后被选为默认的混合模式。一般的情况下是我们代码是在
在jdk7以后出现clinet编译器和server编译器,默认为client模式运行,jdk8以后被选为默认的混合模式。一般的情况下是我们代码是在解释执行下,进行运行,当到达一定阈值触发即时编译。
分层编译
对响应速度快,启动速度快有要求的情况下可以使用client模式(c1),对吞吐峰值有要求,但是可以忍受一定延迟性的需求,可以使用server模式(c2)。jdk8以后使用折中的方式编译代码,即有c1的响应速度,又可以有c2的吞吐,性能峰值。
在分层编译中,编译器将执行状态分为5个层次:
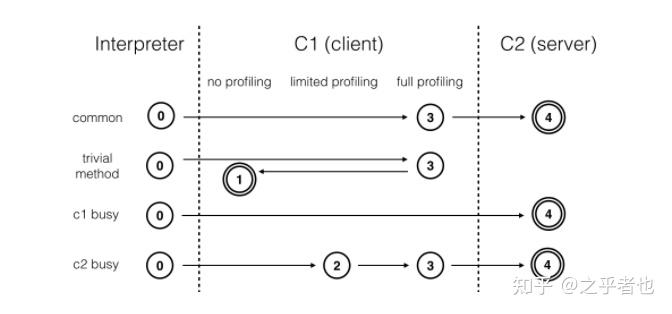
0.解释执行。
1.执行不带profile的c1代码。
2.执行仅仅只有循环回边和方法调用次数profile的c1代码。
3.执行全量的profile的c1代码。
4.执行c2代码。
注:性能上2层,3层性能依次降低。
在上图中,1和4为编译终止态。
在c1繁忙的情况,会直接跳过c1的编译过程,直接进行c2编译
在c2繁忙的情况,c1会经过2,3层编译之后,再由c2编译。
触发条件
jvm根据循环回边次数和方法调用次数总和来判断是否会触发即时编译
-XX:CompileThreshold
在不启动分层编译下:c1为1500触发编译,c2为10000触发编译
在启动分层编译下:会动调整次数,触发编译:
系数的计算方法为:ns = queue_size_X / (TierXLoadFeedback * compiler_count_X) + 1nn阈值设定 -XX:CompileThreshold = 1500n触发调用条件ncts = 1500 * snn其中X是执行层次,可取3或者4;nqueue_size_X是执行层次为X的待编译方法的数目;nTierXLoadFeedback是预设好的参数,其中Tier3LoadFeedback为5,Tier4LoadFeedback为3;ncompiler_count_X是层次X的编译线程数目,会根据cpu核心数来自动指定,c1:c2 比例为1:2
优化
- profile 优化
profile是指在程序运行期间,动态的收集数据运行状态的数据。
- 基于分支profile的优化
public void test(int k){n int result = 0;n if(k == 0){n result = 1;n }else if(k == 1){n result = 2;n }n}
在上面的代码里,虚拟机会不断收集调用这个profile信息,如果这这方法一直只进行一个分支的判断,虚拟机就会推断,程序不会走另一个分支,即时编译器就会省略掉一个,只对一个分支进行编译为机器码。
例如:
public void test(int k){n result = 1;n}
- 基于类型profile的优化
与分支优化相似,直接上代码
public void test(Object obj){n if(obj instanceof Dog){n //this is dogn }n if(obj instanceof Cat){n //this.catn }n}
编译器同样会判断是不是只走了一个逻辑,来进行代码优化编译
- 方法内联
方法内联:在程序执行期间,编译器会把被调用方法里的逻辑,直接纳入到调用方法中。
内联条件:强制内联,IR图,方法大小,调用次数,热点代码。
在jvm准备阶段,会把符号引用转化为实际引用,编译器会根据这些引用将方法纳入进来。
但是对虚方法是运行期间才能确定方法调用,需要进行去虚化处理。
jvm方法调用 - 搜索结果 - 知乎条件去虚化:进行类型比较,是将实现类一个个全部放入代码段中。
public interface Annimal{n void apply()n}npublic class Dog implements Annimal{n public void apply(){n //TODOn }n}npublic class Cat implements Annimal{n public void apply(){n //TODOn }n}n//转换前npublic void add(Annimal a){n a.apply(){n }n}n//转换后npublic void add(Annimal a){n if(a.getClass() == Cat.class){n n }n if(a.getClass() == Dog.class){nn }n}
完全去虚化:在全类中查找,如果只有一个类型,那么直接内联,由于无法判断这一次加载的类是否字类实现,需要在每次加载类的时候,都要进行判断。
- 逃逸分析
编译器根据这段代码或者这个对象是不是会被未知的引用所引用,如果无法判断,可能会被未知引用,那么就会判断为逃逸分析,不会对它进行优化。
标量替换:在java内存,对象并不会存储在栈上面,如果这段代码,为热点代码,编译器会把对象中的内容,直接替换为值替代,减少压栈,弹栈,堆内存的大小。
锁消除:
synchronized(new object){}
这种代码,每一次加锁都会创建一个单独锁,这和没有加锁一样,编译器会去掉这段逻辑
分支优化:
public void test(boolean f){n Object obj = new Object();n if (f){n System.out.println(f);n }n}
如果有99% (大概值)的执行逻辑不会执行到这里,就会判断不会逃逸,会对齐进行优化为
public void test(boolean f){n if (f){n Object obj = new Object();n System.out.println(f);n }n}
去优化
OSR去优化:在即时编译中,在对循环回边进行的统计的时候,会在执行代码出,插入trap函数,当执行机器码的时候,由一段逻辑,与即时编译优化判断,不符合的时候,虚拟机会回退会解释执行,而这些trap函数,就是回归解释执行,执行未优化之前代码。
上一篇:美即好效应








