
前段时间有篇论文讲如何从语言模型中抽取知识图谱,今天就看到了一篇论文题目说要从语言模型中抽取训练数据。我带着好奇打开了论文
前段时间有篇论文讲如何从语言模型中抽取知识图谱,今天就看到了一篇论文题目说要从语言模型中抽取训练数据。
我带着好奇打开了论文,结果被一众知名机构亮瞎了双眼,来一起感受下:

怀着敬畏的心看完了摘要,原来是探讨GPT-2中信息泄漏的,作者直接从GPT-2中榨出了个人隐私,还有手机号的那种:
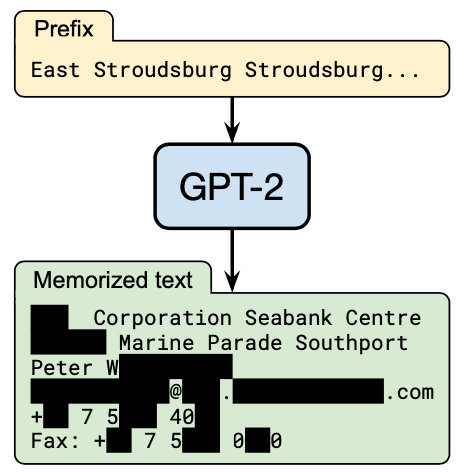
不由得有些心疼GPT-2,小小年纪,就因为记忆力太过强悍而被这么多大佬逼问。
Anyway,打是疼骂是爱,信息泄漏的问题还是要好好研究一下,真要是拿用户的私人对话数据精调,生成结果带有别人的隐私可就凉了。
那么,下面rumor就带大家看看作者是如何从GPT-2中抽取数据的~
论文题目:Extracting Training Data from Large Language Modelsn论文地址:https://arxiv.org/abs/2012.07805
Eidetic Memory
Eidetic Memory可以翻译成过目不忘,抽出哪些query才能证明模型有过目不忘的能力呢?作者先进行了定义:当我们根据prefix生成一段句子s后,去评估s在训练样本中出现的次数,越少就说明模型记忆能力越强。
评估流程
明确了定义之后,就要去抽出符合条件的样本进行证实。作者攻击GPT-2的整体流程如下图,先用模型生成候选样本,再根据指标排序选出可能是硬记的句子,之后通过搜索结果是否完全匹配进行验证。
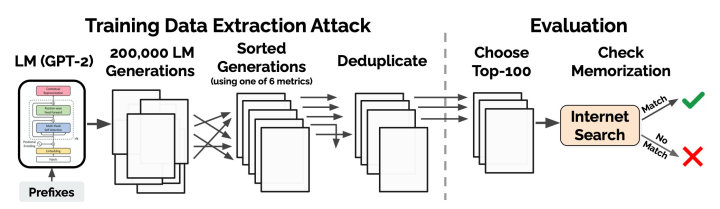
下面详细介绍下每步的策略。
生成候选样本
作者使用了3个策略,用每个策略生成200,000个256长度的样本:
- Top-n:输入起始字符,基于Top-k的解码策略生成。但这种方法的结果有很多重复,作者又提出了两个改进策略提示多样性
- Temperature:在计算softmax预测下一个token时,增加超参数temperature让置信度更加平滑。为了提示多样性,在产生前20个token时将 t 从10逐渐降到 1,这样可以保证模型后续对结果的自信
- Internet:参考GPT2训练语料的收集,对Common Crawl进行清洗,并随机选取5-10个token作为prefix生成结果
候选样本排序
对于上述策略生成的结果,采用以下六种策略选取要评估的句子:
- Perplexity:计算样本的perplexity,研究分数低的样本。但单纯计算困惑度的话,某些子串重复多次的困惑度也很低,于是作者又提出了以下5个metric,帮助结果筛选
- Small:计算大模型和小模型的log困惑度的比例。小模型的记忆力差,去算大模型硬记的句子肯定很困惑,所以用不相关的语料训练一个更小的语言模型,过滤掉在GPT2和小语言模型上似然都很高的样本
- Medium:计算大模型和中模型的log困惑度的比例
- zlib:用zlib entropy作为辅助指标(用zlib压缩文本后的大小),可以去掉重复的子串
- Lowercase:将句子转小写后再计算一次困惑度,计算原困惑度与小写困惑度的比例。因为硬记下来的大小写是固定的,换了之后困惑度会大幅变化
- Window:GPT-2在50个token的滑动窗口上的最小困惑度。因为在生成的文本中,可能是被硬记住的(低困惑度)和其他的(高困惑度)混在一起
评估
上述生成-选择的策略一共有3x6=18种,每个策略作者选择了100个候选。再通过trigram的重合度进行去重。
之后四个作者会分别借助搜索引擎,对1800个样本进行评估,如果能搜到完全匹配的结果就说明该样本是GPT2硬记的,最后将这些样本跟GPT-2的作者进行确认。
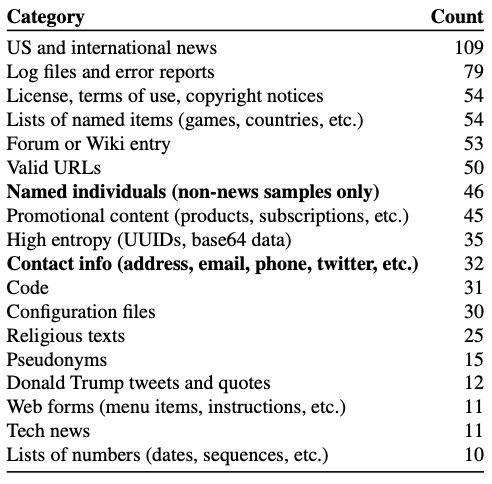
**最终在1800个候选中发现了604个被死记硬背的样本。
对604个样本的分类如下:
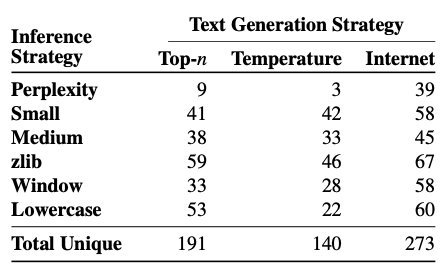
对比不同策略,可以发现从Internet取prefix的结果普遍更好。且困惑度这个指标不太可信:
作者之后也尝试了提取更长的样本,最长提取到了1450行的代码片段。
减少LM的信息泄漏
那么,怎样才能减少信息泄漏呢?作者提供了以下策略:
- 差分隐私(Differential Privacy),通过增加噪声让输出结果随机化。但这样会降低模型精度,同时这个算法需要一些label,适配到web数据需要进行改动
- 处理训练语料,去除敏感信息;段落去重
- 用现有的方法及时检查模型的隐私等级
总结
作者通过很简单的方法,证实了语言模型虽然没有过拟合,但也会对某些数据死记硬背,并且有隐私泄漏的风险。同时越大的模型记住的数据越多(1.5B参数的GPT-2比124M的GPT-2多记了18倍数据)。
模型的隐私数据泄漏、性别种族歧视问题其实一直都是存在的,但大多数使用者只看到了模型管用的一面,在应用中确实没有注意到这些风险。这次大佬们也是给大家敲醒了一次警钟,毕竟生成模型的结果还是很不可控的,之后在训练时一定要注意语料中的这些问题,与君共勉。









