医学大模型
一 华驼(HuaTuo)大模型HuaTuo是经过中文医学指令微调(Instruct-tuning) 的LLaMA-7B模型,在微调后提高了LLaMA在医疗领域的问答效果
一 华驼(HuaTuo)大模型
HuaTuo是经过中文医学指令微调(Instruct-tuning) 的LLaMA-7B模型,在微调后提高了LLaMA在医疗领域的问答效果(存在疑问,如何进行评价的)。
1 数据
采用公开和自建的中文医学知识库,并利用GPT3.5接口围绕医学知识库构建问答数据构建了中文医学指令数据集。数据集分为instruction、input和output三部分,格式如下:
{"instruction": "一个患者的卵巢小细胞癌转移至其它部位,是否有必要进行手术治疗?"n "input": "", n"output": "当卵巢小细胞癌转移至其它部位时,手术治疗的效果可能不理想,因此一般不推荐进行手术治疗。针对转移病灶,可以采用化疗、放疗等治疗手段进行综合治疗。"}
此外收集了2023年关于肝癌疾病的中文医学文献,利用GPT3.5接口围绕医学文献多轮问答数据。数据集分为instruction、input和output三部分,instruction又包括user和bot两部分,格式如下:
{"instruction": " <user>: 我听说免疫疗法是治疗晚期肝癌的一种很有效的方法,真的吗? n<bot>: 是的,免疫疗法是一种新兴的治疗方法,它可以提高人体免疫系统对癌细胞的反应能力。对于晚期肝癌患者,免疫疗法已证明具有很高的治疗效果。 n<user>: 但是,这是否适用于所有的肝癌患者?", n"output": "不是所有的肝癌患者都适合进行免疫疗法。根据患者的临床表现和病情,医生会对患者进行评估,从而选择最适合的治疗方案。",n "input": ""}
2 训练
2.1 训练资源需求
在一张A100-SXM-80GB显卡上进行了训练,训练总轮次10轮,耗时约2h17m。batch_size=128的情况下显存占用在40G左右。预计3090/4090显卡(24GB显存)以上显卡可以较好支持,根据显存大小来调整batch_size。(稍后试试)
2.2 微调代码
常规Lora训练流程。(之后有时间写分析)
3 推理
推理方式分为三种,区别在于加载的LoRA权重不同和是否支持多轮。加载的LoRA权重分为对LLaMA和Alpaca进行指令微调的LoRA权重文件,并可以进一步划分为基于医学知识库和医学文献的LoRA权重。
#基于医学知识库nbash ./scripts/infer.shnn#基于医学文献n#单轮nbash ./scripts/infer-literature-single.shnn#多轮nbash ./scripts/infer-literature-multi.sh
4 实验结果
方案中的几个测试用例,好坏无法按照几个案例来评价,应该进行更多测试。
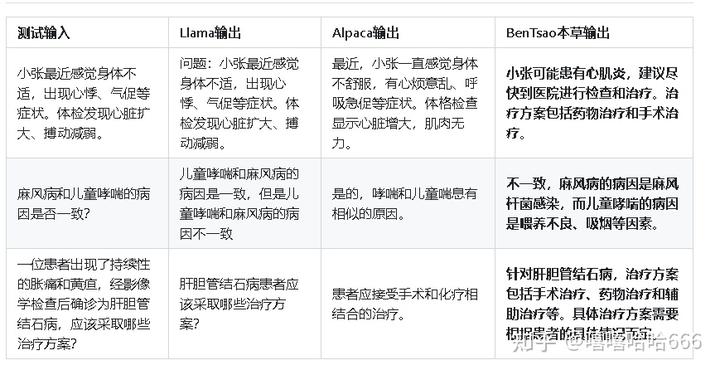
没扩充llama词表不知道是否有影响。
项目由哈尔滨工业大学社会计算与信息检索研究中心健康智能组完成,项目链接:
SCIR-HI/Huatuo-Llama-Med-Chinese: Repo for BenTsao [original name: HuaTuo (华驼)], Llama-7B tuned with Chinese medical knowledge. 本草(原名:华驼)模型仓库,基于中文医学知识的LLaMA模型指令微调 (github.com)二 DoctorGLM
基于 ChatGLM-6B的中文问诊模型。
项目地址:
xionghonglin/DoctorGLM: 基于ChatGLM-6B的中文问诊模型 (github.com)三 MedicalGPT-zh
基于ChatGLM-6B LoRA 16-bit指令微调的中文医疗通用模型。
项目地址:
GitHub - MediaBrain-SJTU/MedicalGPT-zh: MedicalGPT-zh:一个基于ChatGLM的在高质量指令数据集微调的中文医疗对话语言模型四 ChatDoctor
英文版,一个基于LLaMA的在医疗领域的大模型。
项目地址:
Kent0n-Li/ChatDoctor (github.com)五 MedQA-ChatGLM
GitHub - WangRongsheng/MedQA-ChatGLM: ️ 基于真实医疗对话数据在ChatGLM上进行LoRA、P-Tuning V2、Freeze、RLHF等微调,我们的眼光不止于医疗问答六 visual-med-alpaca
多模态大模型
https://github.com/WangRongsheng/XrayGLM七 LMFlow
英文版,基于PubMedQA和MedMCQA构建了instruction数据集,使用8*A100,微调约16个小时得到LLaMA-33B(LoRA)模型,在医疗问题上的效果优于ChatGPT。
项目地址:
OptimalScale/LMFlow: An Extensible Toolkit for Finetuning and Inference of Large Foundation Models. Large Model for All. (github.com)八 Baize
英文版。模型调优的数据来自Quora和Medical对话,基于LLaMA-7B微调得到。
项目地址:
project-baize/baize-chatbot: Let ChatGPT teach your own chatbot in hours with a single GPU! (github.com)九 Med-PaLM
英文版,Google的工作。在PaLM的基础上加了instruction prompt tuning,具体工作见《Large Language Models Encode Clinical Knowledge》,不是很常见。
项目地址:
2212.13138.pdf (arxiv.org)十 Visual-Med-Alpaca
英文版,在文本侧,基于gpt-3.5 turbo和human共同合作构建的指令数据集。支持多模态的问答
项目地址:
Visual Med-Alpaca参考链接:
中文医疗大模型的2W1H分析上一篇:警用热成像仪






