
项目背景使用脱敏后的锅炉传感器采集的数据,预测锅炉产生的蒸汽量。可以判断预测的结果是连续性数值变量,属于回归预测求解一、数据
项目背景
使用脱敏后的锅炉传感器采集的数据,预测锅炉产生的蒸汽量。可以判断预测的结果是连续性数值变量,属于回归预测求解
一、数据探索
1.1使用pandas的read_scv函数读取训练集与测试集,并且使用info与describe函数查看
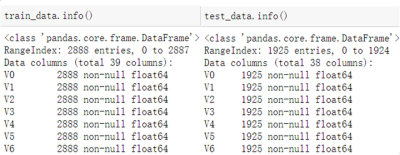
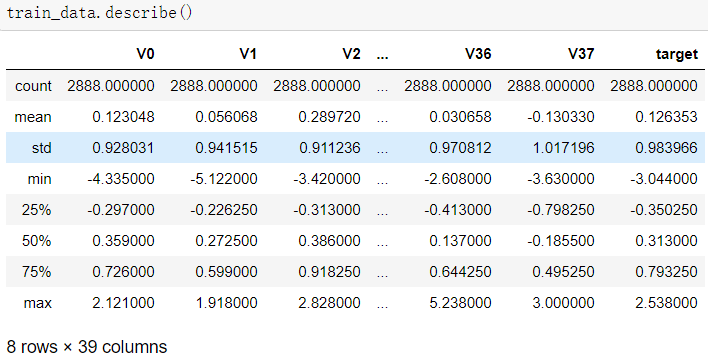
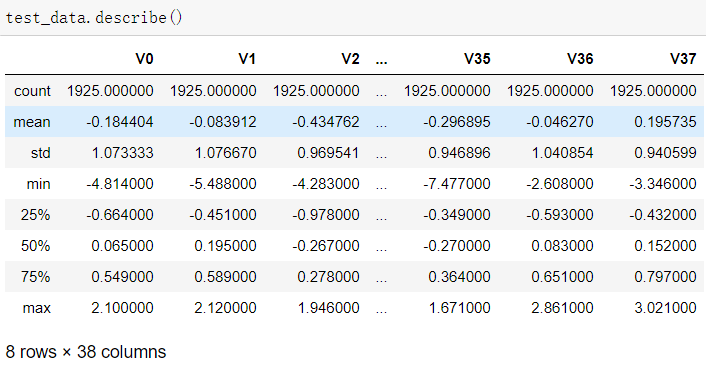
可以发现,训练集有2888个样本,测试集有1925个样本;特征变量相同,为V0~V37共38个(由于数据采取了脱敏处理,特征的具体含义不明),训练集比测试集多了一个target项。数据类型为浮点型,变量为数值型与连续型。
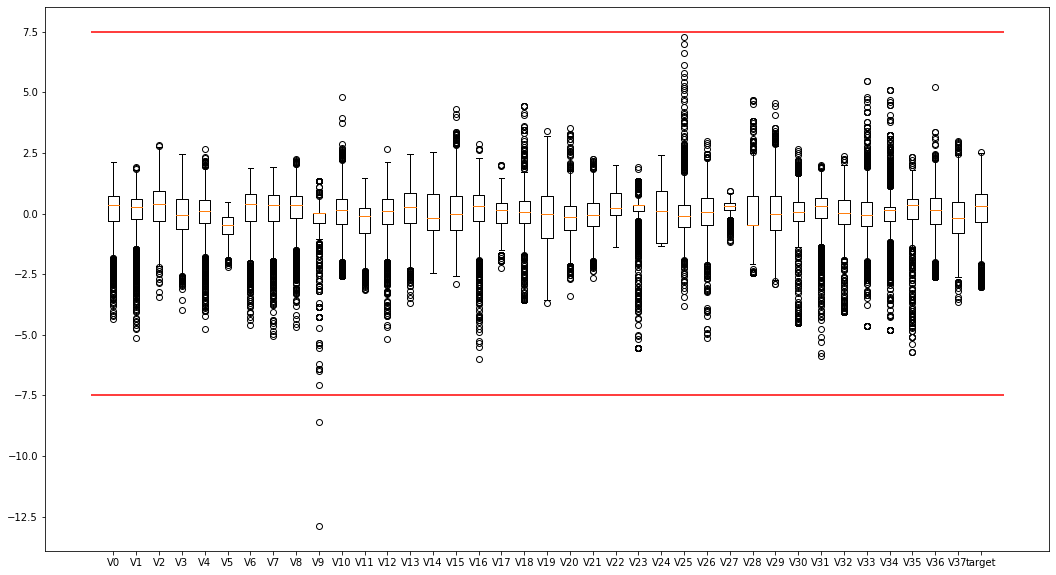
1.2使用箱线图查观察特征的数值分布

如图,发现较多偏离值,许多特征的点位于四分位外,尤其是V9,可以考虑移除
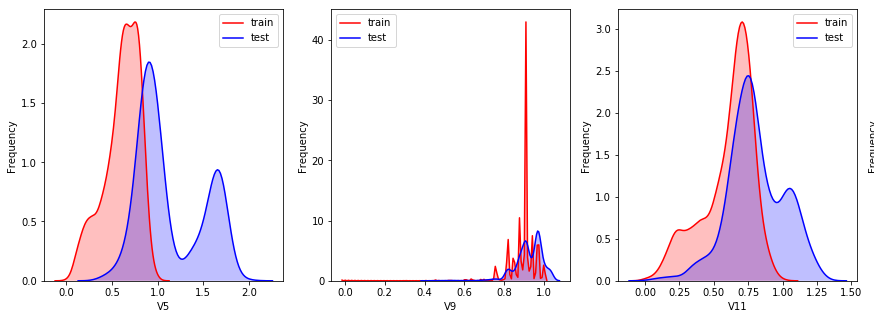
1.3通过绘制KDE分布图,比对训练集与测试集中的特征变量的分布情况
对比后我们发现:特征V5、V9、V11、V17、V22,V28的值在训练集测试集中分布差异较大,会影响模型泛化能力,需要删除。
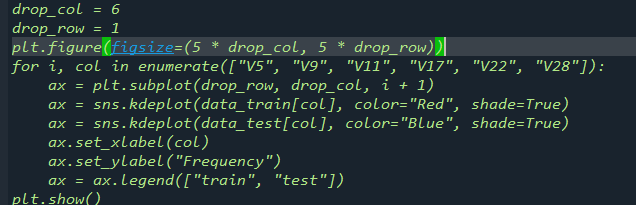

1.4使用直方图、Q-Q图来观察特征的分布是否近似静态分布,并且使用线性关系图来观察特征与tager是否构成线性关系

从中可以看出,特征的情况有多种的排列组合,例如有的特征分布符合正态,可以考虑对齐进行Box-Cox变换,还有的特征与tager线性相关很差,就要考虑到使用非线性相关模型开处理
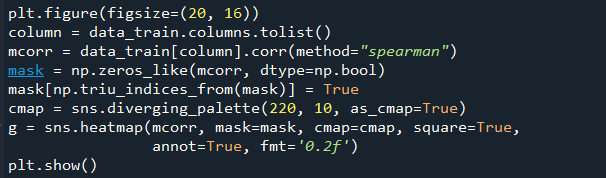
1.5以热力图的方式,展现特征之间的相关性
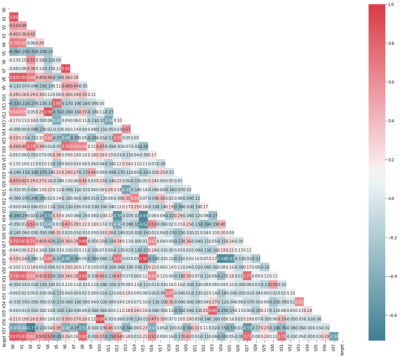
从图中可以看出,在这37个特征之间,拥有着的强相关性不在少数。例如:V8、V27、V31就分别跟V0、V1有着强的正关(0.75以上);V15就跟V24、V25有着强负相关(-0.6以上),目测类似的还有十几组,这会导致共线性影响的概率增大,从而影响模型精度。所以可以考虑使用PCA对数据进行处理,去掉多重共线性
二、特征工程
能够确定下来的步骤,就是对数据进行归一化处理,然后删除训练集与测试集分布不一致的特征,至于下一步的处理,得参考模型的MSE,于是建立一个bagging的集成模型来模拟最终模型(stacking的集成),使用GBDT、随机森林、XGB作为基模型,采用5折交叉验证的方式,对训练集进行试跑分。
1.1只进行归一化处理,删掉分布不一致的特征,得到的MSE为:0.1323
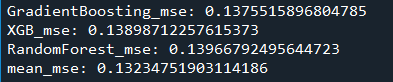
1.2在1.1的基础上,对数据进行Box-Cox变换,得到的MSE为:0.1321
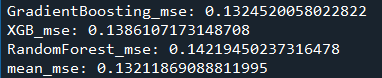
1.3,在1.2的基础上对数据进行PCA降维,保留原来特征90%信息,得到的MSE为:0.1587

运行后,只剩下了16个主特征,但是MSE反而升高了,所以舍弃这步骤.
1.4,在1.2的基础上,对数据进行对数处理,使特征更符合正态分布,得到的MSE为:0.1332

1.5在1.4的基础上,对数据进行PCA降维,保留原来特征90%信息,得到的MSE为:0.1585

最终选择1.2的步骤
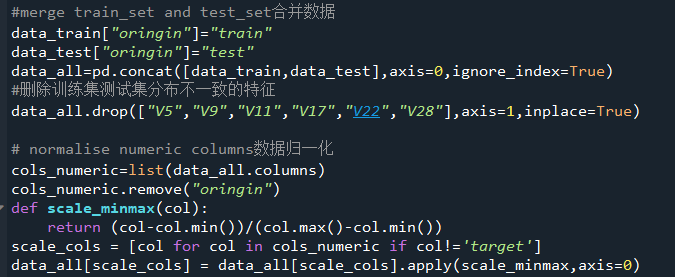

评估用的模型在:算法评估.py

处理后的数据,另存为新文件

四、训练模型
项目为阿里天池竞赛,根据经验一般,使用Xgboost、Lightgbm以及集成模型的得分较高,固不考虑单模型。
采用stacking的形式进行模型融合,分成两层。第一层由若个基模型组成,这里选择了随机森林跟GBDT,其输入为原始训练集,每一个模型采用5折交叉来训练模型,形成了对整一个训练数据的标签的预测,然后预测结果按顺序堆叠起来——以此作为新的训练集的特征;使用4折预测出来的模型,对测试集进行预测,多少折模型就有多少份预测,然后对这些预测取平均值——以此作为新的测试数据的标签。
基模型训练完毕后,把训练后的结果作为1个特征,这里就有了两个新“特征”,与原始特合并后,这样可以使模型的效果更好,还可以防止过拟合
第二层的模型选用lightgbm,则是以第一层基模型的输出新训练集进行训练,并且以新数据标签进行交叉验证,然后得到完整的stacking模型,最后对数据进行预测。
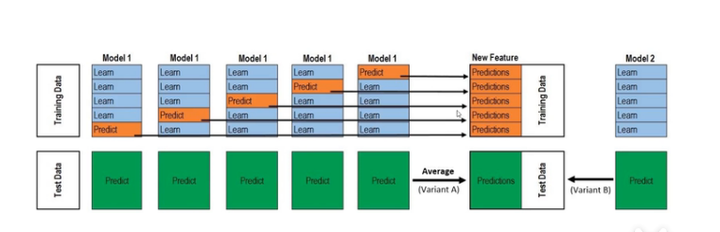

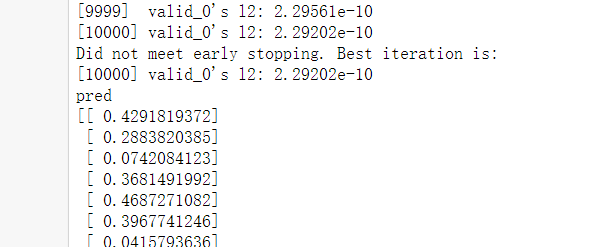
训练过程
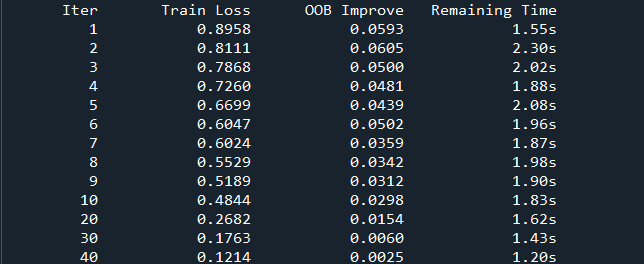
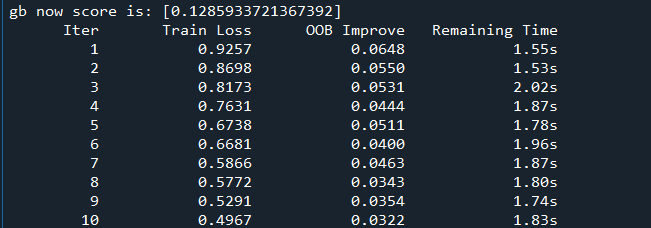
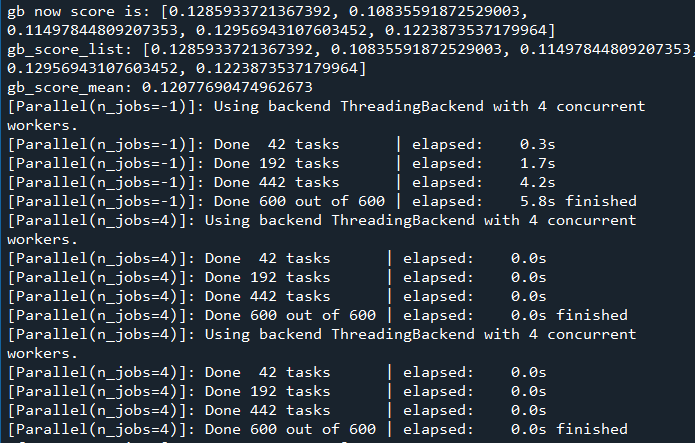
打印结果
代码、数据链接如下
熟练工人/工业蒸汽预测问:2023年锅炉价格/多少钱?
上一篇:成都流云
下一篇:渔夫的野望:热泵蒸汽机








